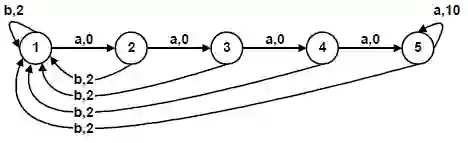
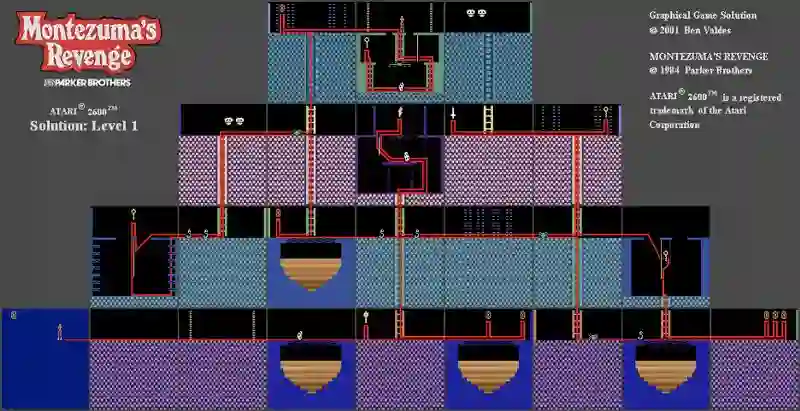
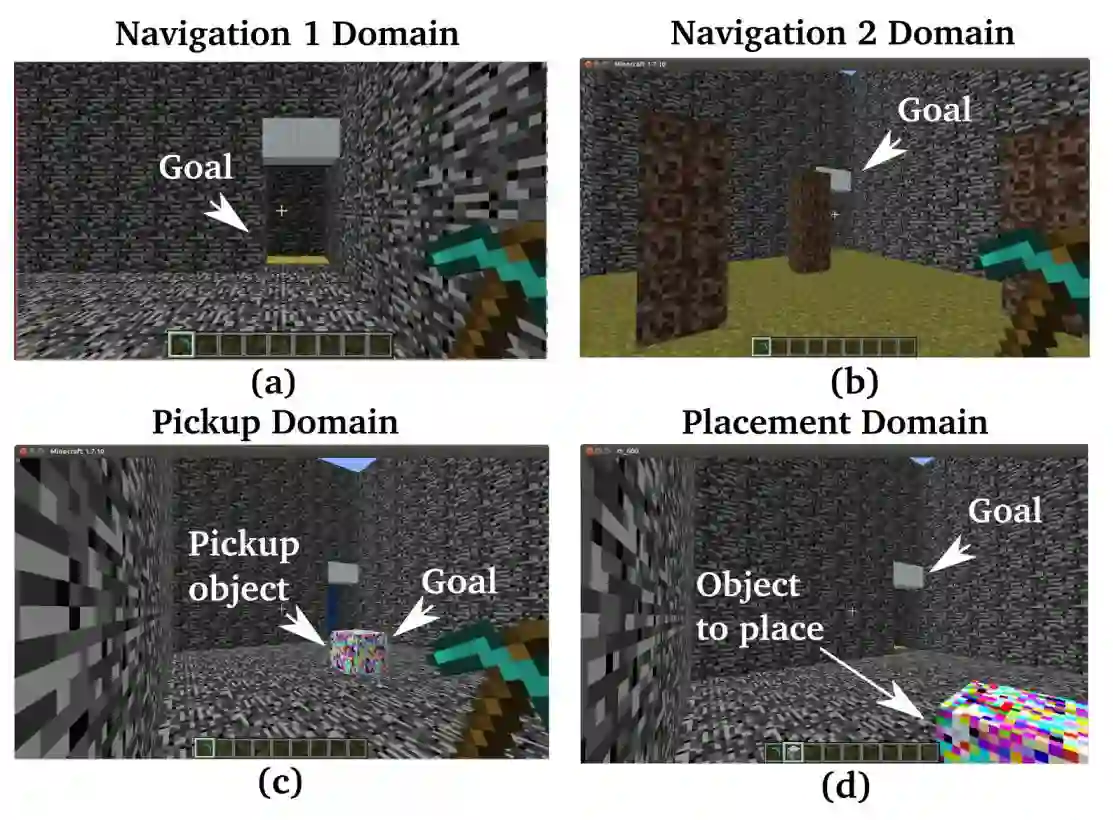
Deep Reinforcement Learning (DRL) and Deep Multi-agent Reinforcement Learning (MARL) have achieved significant success across a wide range of domains, such as game AI, autonomous vehicles, robotics and finance. However, DRL and deep MARL agents are widely known to be sample-inefficient and millions of interactions are usually needed even for relatively simple game settings, thus preventing the wide application in real-industry scenarios. One bottleneck challenge behind is the well-known exploration problem, i.e., how to efficiently explore the unknown environments and collect informative experiences that could benefit the policy learning most. In this paper, we conduct a comprehensive survey on existing exploration methods in DRL and deep MARL for the purpose of providing understandings and insights on the critical problems and solutions. We first identify several key challenges to achieve efficient exploration, which most of the exploration methods aim at addressing. Then we provide a systematic survey of existing approaches by classifying them into two major categories: uncertainty-oriented exploration and intrinsic motivation-oriented exploration. The essence of uncertainty-oriented exploration is to leverage the quantification of the epistemic and aleatoric uncertainty to derive efficient exploration. By contrast, intrinsic motivation-oriented exploration methods usually incorporate different reward agnostic information for intrinsic exploration guidance. Beyond the above two main branches, we also conclude other exploration methods which adopt sophisticated techniques but are difficult to be classified into the above two categories. In addition, we provide a comprehensive empirical comparison of exploration methods for DRL on a set of commonly used benchmarks. Finally, we summarize the open problems of exploration in DRL and deep MARL and point out a few future directions.
翻译:深度强化学习(DRL)和深度多试剂强化学习(MARL)等一系列领域取得了巨大成功,例如游戏AI、自主飞行器、机器人和金融等。然而,众所周知,DRL和深度MARL的试剂样本效率低,而且通常即使是相对简单的游戏环境也需要数百万个互动,从而防止了在现实产业情景中的广泛应用。背后的一个瓶颈挑战是众所周知的勘探问题,即如何有效探索未知的环境和收集对政策学习最有帮助的信息性经验。在本文件中,我们对DRL和深度MARL的现有勘探方法进行了全面调查,目的是就关键问题和解决办法提供理解和见解。我们首先确定了实现高效勘探的几项关键挑战,而大多数勘探方法的目的是解决这些挑战。然后,我们通过将现有方法分为两大类:以不确定性为导向的探索和内在动机为导向的探索。 面向不确定性的探索的本质是利用我们所了解的和深度不确定性的不确定性,从而将我们所了解和深度的精细的精细的精细的精确度用于在深度的探索过程中得出高效的探索的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的细的精细的精细的精细的精细的精细的精细的细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的精细的细的精细的精细的精细的精细的精细的精细的精细的精细的精细的细的细的精细的