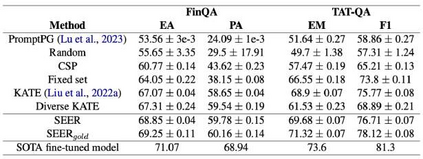
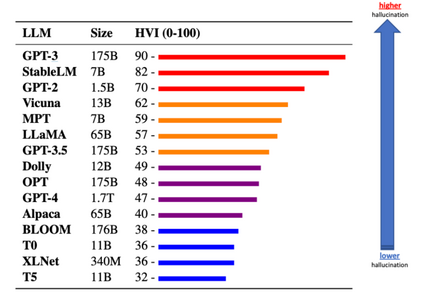
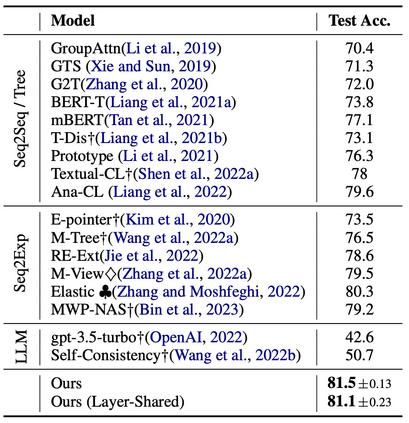
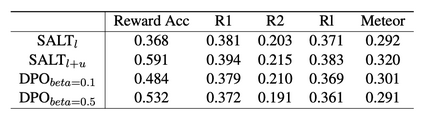
Existing benchmarks for evaluating foundation models mainly focus on single-document, text-only tasks. However, they often fail to fully capture the complexity of research workflows, which typically involve interpreting non-textual data and gathering information across multiple documents. To address this gap, we introduce M3SciQA, a multi-modal, multi-document scientific question answering benchmark designed for a more comprehensive evaluation of foundation models. M3SciQA consists of 1,452 expert-annotated questions spanning 70 natural language processing paper clusters, where each cluster represents a primary paper along with all its cited documents, mirroring the workflow of comprehending a single paper by requiring multi-modal and multi-document data. With M3SciQA, we conduct a comprehensive evaluation of 18 foundation models. Our results indicate that current foundation models still significantly underperform compared to human experts in multi-modal information retrieval and in reasoning across multiple scientific documents. Additionally, we explore the implications of these findings for the future advancement of applying foundation models in multi-modal scientific literature analysis.
翻译:暂无翻译