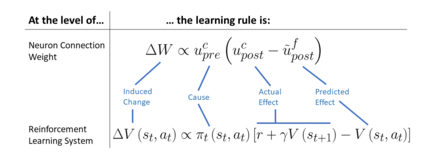
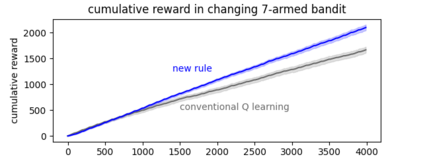
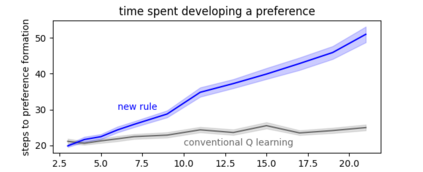
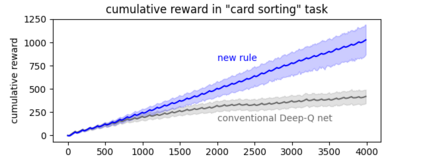
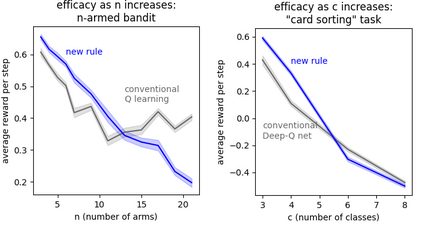
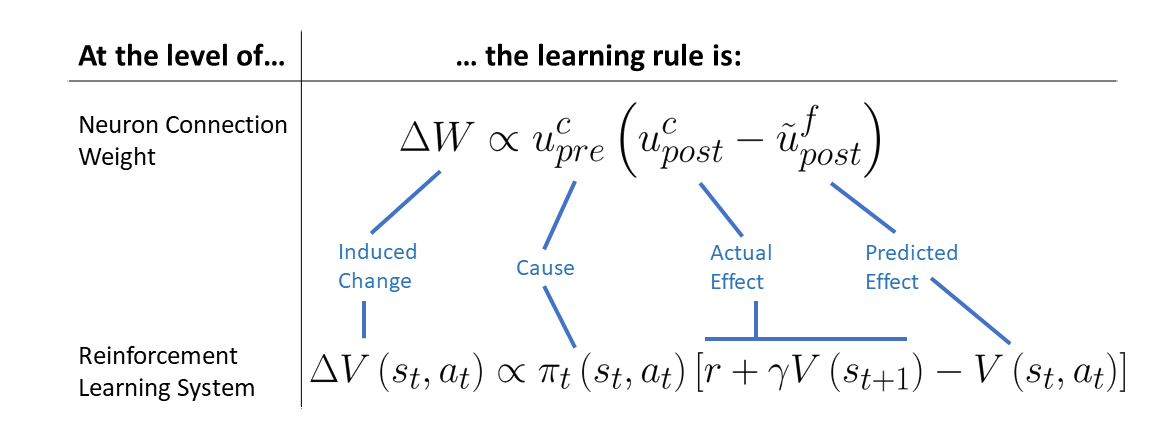
Developments in reinforcement learning (RL) have allowed algorithms to achieve impressive performance in highly complex, but largely static problems. In contrast, biological learning seems to value efficiency of adaptation to a constantly-changing world. Here we build on a recently-proposed neuronal learning rule that assumes each neuron can optimize its energy balance by predicting its own future activity. That assumption leads to a neuronal learning rule that uses presynaptic input to modulate prediction error. We argue that an analogous RL rule would use action probability to modulate reward prediction error. This modulation makes the agent more sensitive to negative experiences, and more careful in forming preferences. We embed the proposed rule in both tabular and deep-Q-network RL algorithms, and find that it outperforms conventional algorithms in simple, but highly-dynamic tasks. We suggest that the new rule encapsulates a core principle of biological intelligence; an important component for allowing algorithms to adapt to change in a human-like way.
翻译:强化学习(RL)的发展使得算法能够在高度复杂但基本上是静态的问题中取得令人印象深刻的成绩。 相反,生物学习似乎将适应效率看得比一个不断变化的世界要好。 在这里,我们以最近提出的神经学学习规则为基础,假设每个神经元都能通过预测自己的未来活动来优化其能量平衡。这一假设导致一种神经学学习规则,使用预先合成输入来调节预测错误。我们争辩说,类似的RL规则将使用行动概率来调节奖励预测错误。这种调制使该代理商对负面经验更加敏感,并在形成偏好时更加小心。我们把拟议规则嵌入表格和深Q网络RL算法中,发现它优于简单但高度动态的任务中的常规算法。我们建议,新规则包罗出生物智能的核心原则;这是允许算法适应人类变化的重要组成部分。