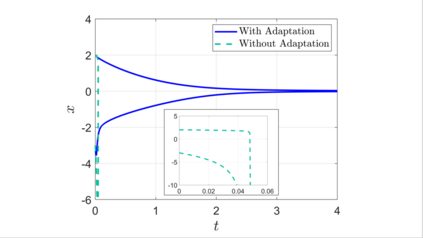
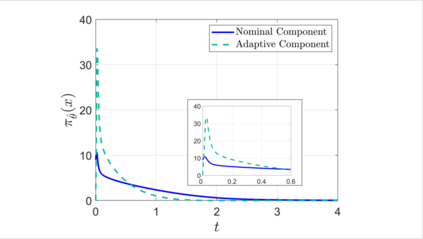
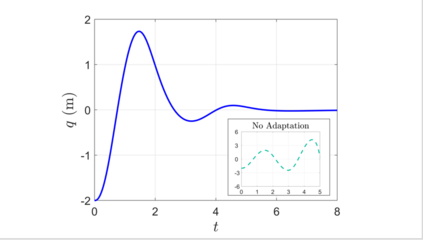
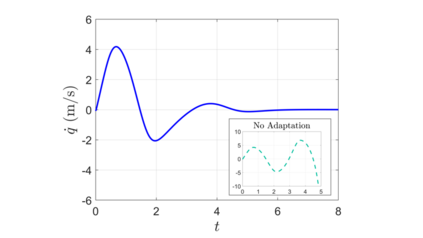
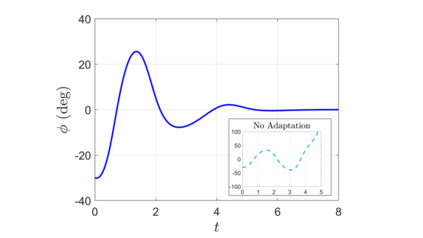
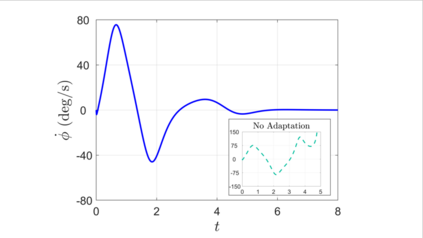
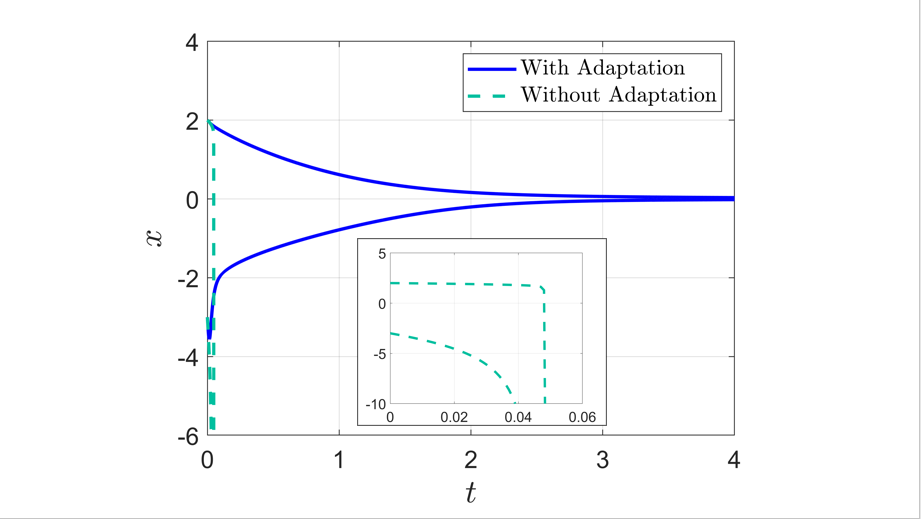
We combine adaptive control directly with optimal or near-optimal value functions to enhance stability and closed-loop performance in systems with parametric uncertainties. Leveraging the fundamental result that a value function is also a control Lyapunov function (CLF), combined with the fact that direct adaptive control can be immediately used once a CLF is known, we prove asymptotic closed-loop convergence of adaptive feedback controllers derived from optimization-based policies. Both matched and unmatched parametric variations are addressed, where the latter exploits a new technique based on adaptation rate scaling. The results may have particular resonance in machine learning for dynamical systems, where nominal feedback controllers are typically optimization-based but need to remain effective (beyond mere robustness) in the presence of significant but structured variations in parameters.
翻译:我们直接将适应性控制与最佳或接近最佳的价值功能结合起来,以加强稳定性和具有参数不确定性的系统中的闭环性能。利用价值功能也是一种控制 Lyapunov 功能这一基本结果,再加上一旦知道一个核心性能控制可以立即使用直接适应性控制这一事实,我们证明从优化政策中得出的适应性反馈控制器的无症状的闭环性融合。解决了匹配性和不匹配的参数差异,后者利用了基于适应率缩放的新技术。结果在动态系统的机器学习中可能特别具有共鸣性,在这些系统中,名义反馈控制器通常以优化为基础,但在参数存在重大但结构化变化的情况下,需要保持效力(超越单纯的稳健性 ) 。