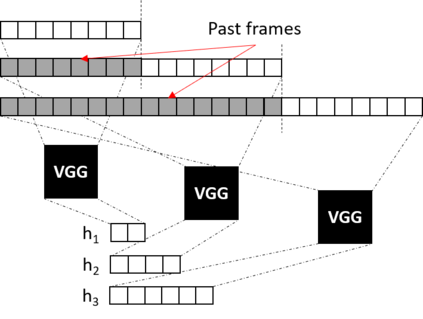
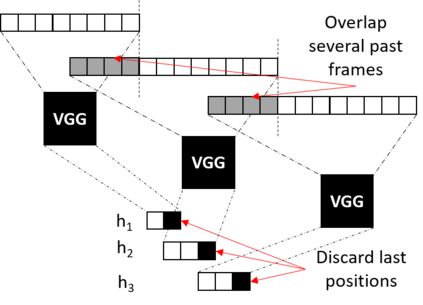
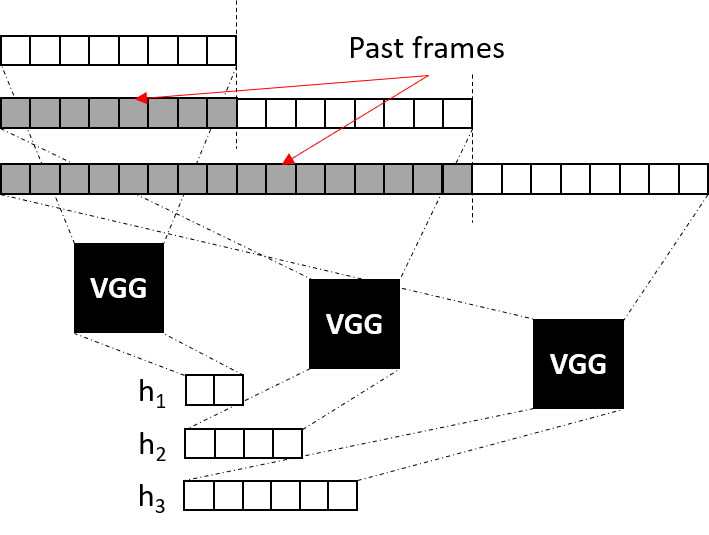
Boosted by the simultaneous translation shared task at IWSLT 2020, promising end-to-end online speech translation approaches were recently proposed. They consist in incrementally encoding a speech input (in a source language) and decoding the corresponding text (in a target language) with the best possible trade-off between latency and translation quality. This paper investigates two key aspects of end-to-end simultaneous speech translation: (a) how to encode efficiently the continuous speech flow, and (b) how to segment the speech flow in order to alternate optimally between reading (R: encoding input) and writing (W: decoding output) operations. We extend our previously proposed end-to-end online decoding strategy and show that while replacing BLSTM by ULSTM encoding degrades performance in offline mode, it actually improves both efficiency and performance in online mode. We also measure the impact of different methods to segment the speech signal (using fixed interval boundaries, oracle word boundaries or randomly set boundaries) and show that our best end-to-end online decoding strategy is surprisingly the one that alternates R/W operations on fixed size blocks on our English-German speech translation setup.
翻译:在 IWSLT 2020 上同步翻译共享任务的推动下,最近提出了充满希望的端对端在线语音翻译方法,其中包括将语音输入(以源语言)逐步编码,并解码相应的文本(以目标语言),同时尽可能在升降和翻译质量之间进行最佳权衡。本文调查了端对端同步语音翻译的两个关键方面:(a) 如何有效地编码连续语音流,和(b) 如何将语音流分解,以便在读(R:编码输入)和写(W:解码输出)操作之间进行最佳的交替。我们扩展了我们先前提议的端对端在线解码战略,并显示在用 ULSTM 编码取代 BLSTM 的同时,会降低离线模式的性能。我们还测量了将语音信号分解的不同方法的影响(使用固定的间距边界、或缩略字字边界或随机设定的边界),并显示我们的最佳端对端对端在线解码战略令人惊讶的是,在固定的语音转换上将 R/W 的操作置于固定的区块上。