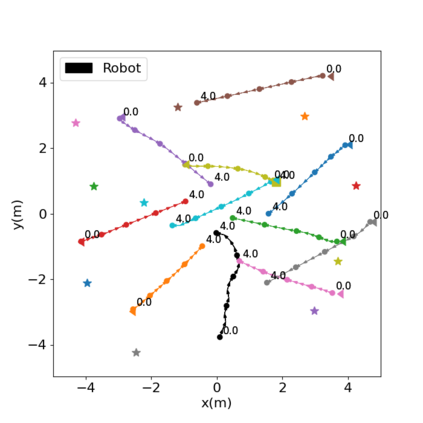
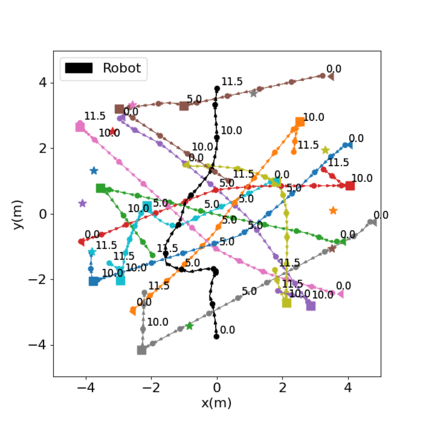
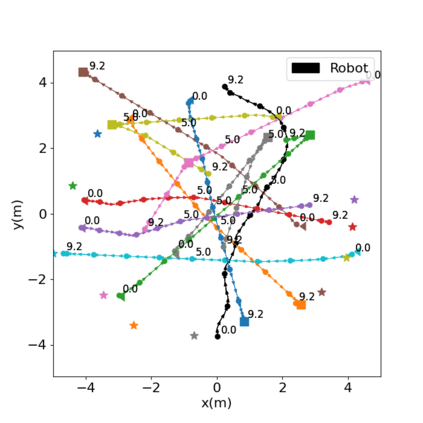
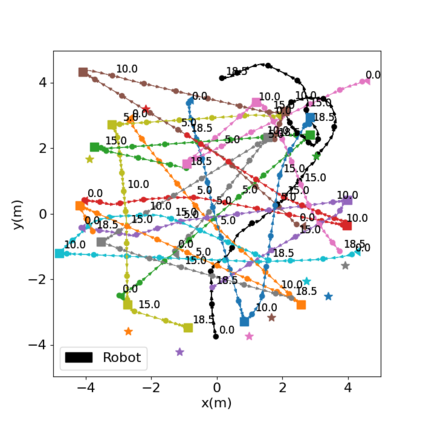
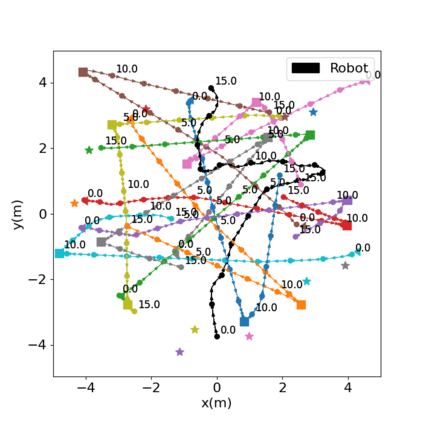
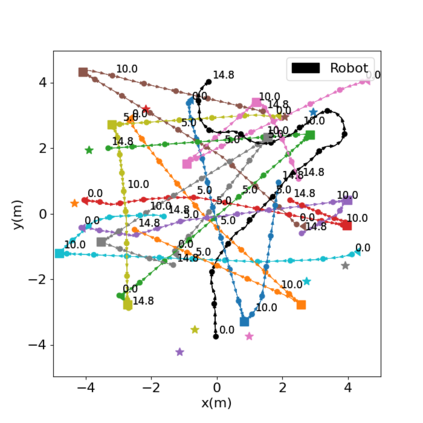
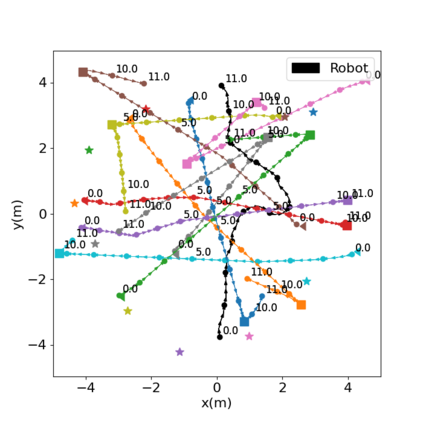
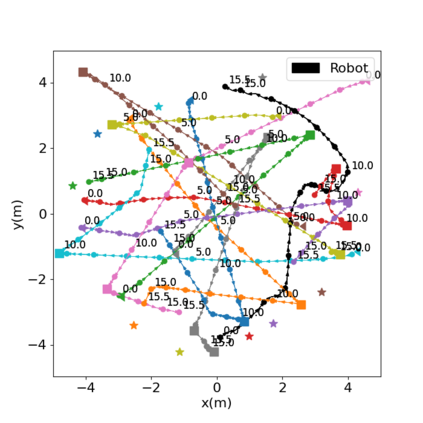
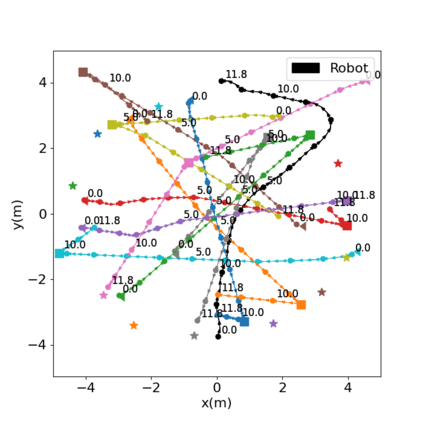
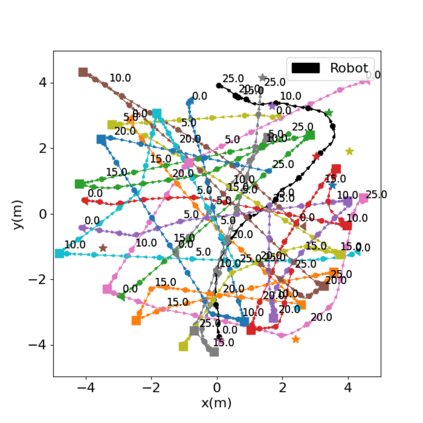
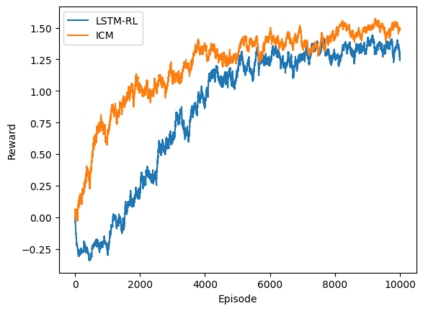
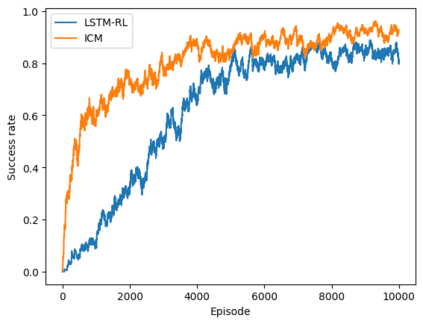
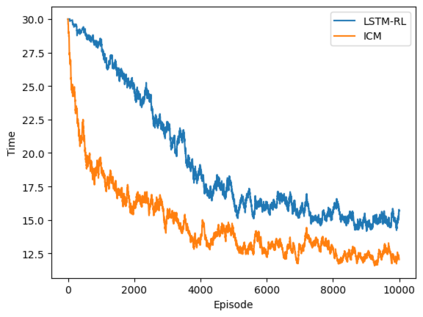
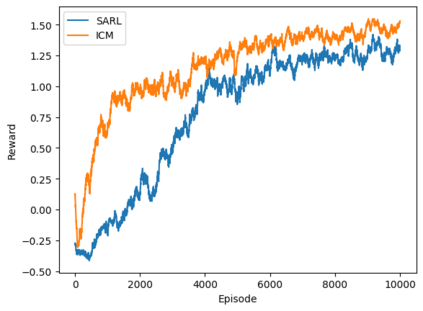
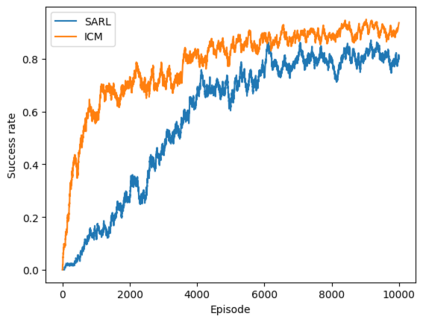
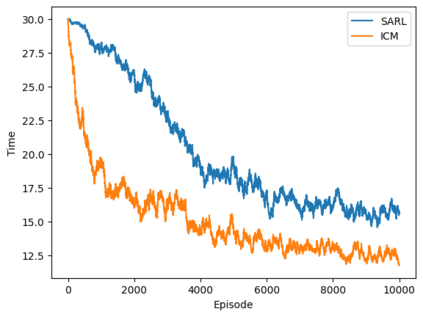
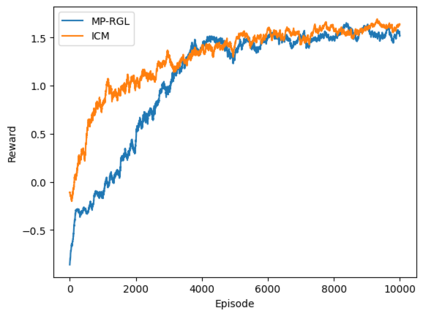
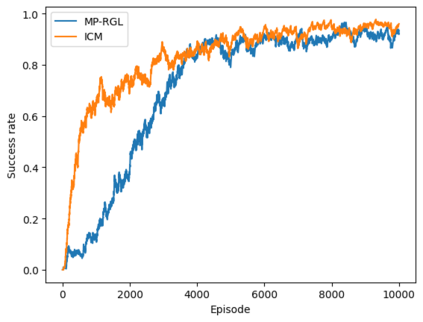
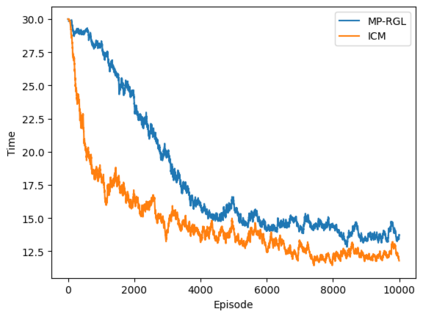
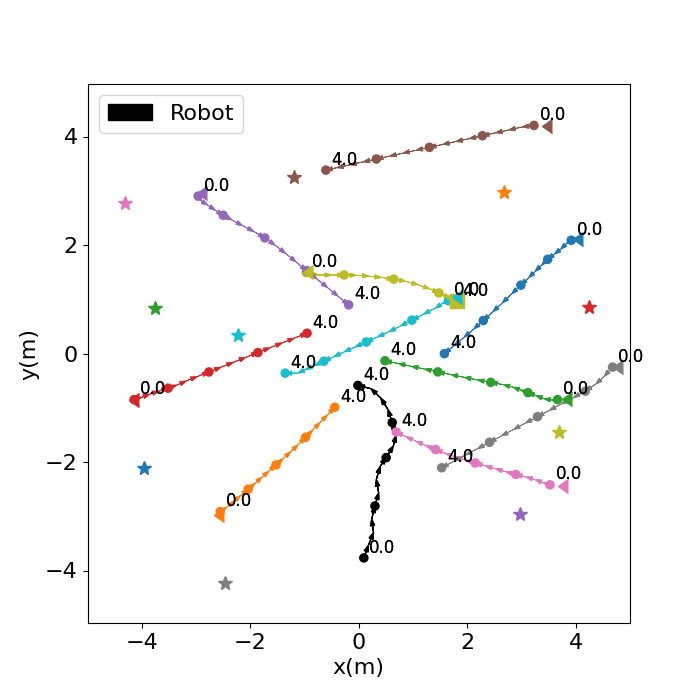
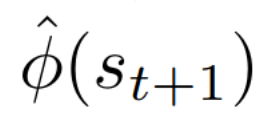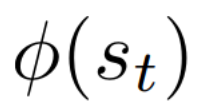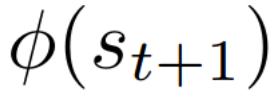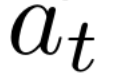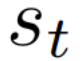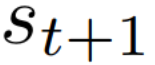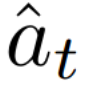Autonomous navigation in crowded environments is an open problem with many applications, essential for the coexistence of robots and humans in the smart cities of the future. In recent years, deep reinforcement learning approaches have proven to outperform model-based algorithms. Nevertheless, even though the results provided are promising, the works are not able to take advantage of the capabilities that their models offer. They usually get trapped in local optima in the training process, that prevent them from learning the optimal policy. They are not able to visit and interact with every possible state appropriately, such as with the states near the goal or near the dynamic obstacles. In this work, we propose using intrinsic rewards to balance between exploration and exploitation and explore depending on the uncertainty of the states instead of on the time the agent has been trained, encouraging the agent to get more curious about unknown states. We explain the benefits of the approach and compare it with other exploration algorithms that may be used for crowd navigation. Many simulation experiments are performed modifying several algorithms of the state-of-the-art, showing that the use of intrinsic rewards makes the robot learn faster and reach higher rewards and success rates (fewer collisions) in shorter navigation times, outperforming the state-of-the-art.
翻译:在拥挤环境中的自主导航是一个开放的问题,有许多应用,对于机器人和人类在未来智能城市共存至关重要。近年来,深强化学习方法已证明优于基于模型的算法。然而,尽管所提供的结果很有希望,但工程无法利用模型提供的能力。在培训过程中,这些工程通常被困在本地的奥地马,无法学习最佳政策。它们无法适当访问和与每一个可能的国家互动,例如接近目标或接近动态障碍的州。在这项工作中,我们提议利用内在收益来平衡勘探和开发之间的平衡,并探索取决于国家的不确定性而不是受培训的时间,鼓励代理人对未知状态更加好奇。我们解释该方法的好处,并将它与其他可用于人群导航的探索算法进行比较。许多模拟实验正在修改一些最新技术的算法,表明使用内在报酬使机器人在较短的导航时间里学习更快和更高的报酬和成功率(更接近碰撞率),从而超越了状态。