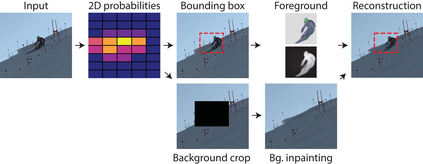
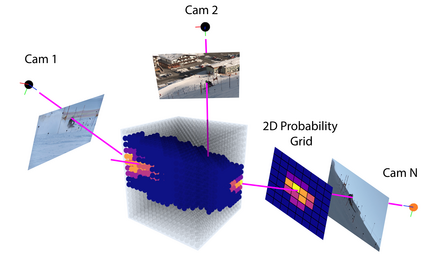
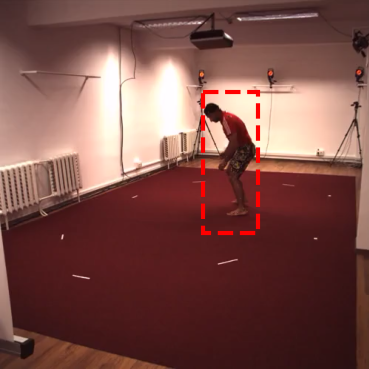
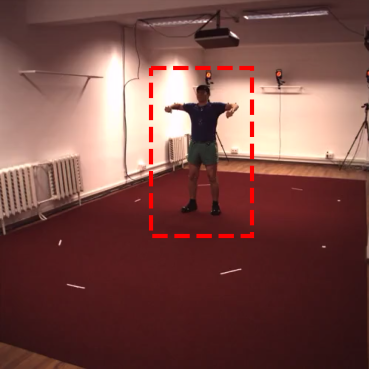
Self-supervised detection and segmentation of foreground objects in complex scenes is gaining attention as their fully-supervised counterparts require overly large amounts of annotated data to deliver sufficient accuracy in domain-specific applications. However, existing self-supervised approaches predominantly rely on restrictive assumptions on appearance and motion, which precludes their use in scenes depicting highly dynamic activities or involve camera motion. To mitigate this problem, we propose using a multi-camera framework in which geometric constraints are embedded in the form of multi-view consistency during training via coarse 3D localization in a voxel grid and fine-grained offset regression. In this manner, we learn a joint distribution of proposals over multiple views. At inference time, our method operates on single RGB images. We show that our approach outperforms state-of-the-art self-supervised person detection and segmentation techniques on images that visually depart from those of standard benchmarks, as well as on those of the classical Human3.6M dataset.
翻译:在复杂场景中,对地表物体进行自我监督的探测和分解正在引起人们的注意,因为完全监督下的对等物体需要大量附加说明的数据,才能在特定领域的应用中提供足够准确性。然而,现有的自我监督方法主要依赖对外观和运动的限制性假设,这不允许在描述高度动态活动的场景中使用这些假设,或涉及摄像运动。为缓解这一问题,我们提议使用多摄像框架,在培训过程中,在通过三维粗微分定位在 voxel 网和细微偏重回归中以多视图一致性的形式嵌入几何限制。这样,我们通过多种观点学习联合分配建议。在推断时间,我们的方法在单一 RGB图像上运作。我们表明,我们的方法在视觉上偏离标准基准的图像以及经典人文3.6M数据集的图像上,超越了最先进的自我监督自我监控人的探测和分解技术。