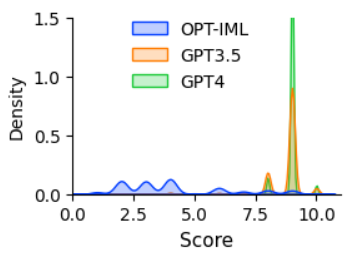
Prior work has shown that finetuning large language models (LLMs) using machine-generated instruction-following data enables such models to achieve remarkable zero-shot capabilities on new tasks, and no human-written instructions are needed. In this paper, we present the first attempt to use GPT-4 to generate instruction-following data for LLM finetuning. Our early experiments on instruction-tuned LLaMA models show that the 52K English and Chinese instruction-following data generated by GPT-4 leads to superior zero-shot performance on new tasks to the instruction-following data generated by previous state-of-the-art models. We also collect feedback and comparison data from GPT-4 to enable a comprehensive evaluation and reward model training. We make our data generated using GPT-4 as well as our codebase publicly available.
翻译:先前的研究表明,使用机器生成的指令跟随数据对大型语言模型(LLMs)进行微调使得这些模型能够在新任务上达到显著的零-shot功能,而不需要人工撰写指令。在本文中,我们首次尝试使用GPT-4生成指令跟随数据进行LLM微调。我们早期在指令调整的LLaMA模型上进行的实验表明,使用GPT-4生成的52K英文和中文指令跟随数据,相对于之前最先进的模型生成的指令跟随数据,在新任务上具有更优秀的零-shot表现。我们还从GPT-4中收集了反馈和比较数据,以便进行综合评估和奖励模型训练。我们公开了使用GPT-4生成的数据以及我们的代码库。