打开模型Zero-Shot新范式:Instruction Tuning

©PaperWeekly 原创 · 作者 | 避暑山庄梁朝伟
研究方向 | 自然语言处理
大规模语言模型已经被证明可以很好的应用到小样本学习任务,例如 OpenAI 提出的 GPT-3 在小样本(few-shot)场景上取得了不错的性能,但是在零样本(zero-shot)学习任务中表现不是很突出。为了提升模型的泛化能力和通用能力,一种新范式诞生了——Instruction Tuning,通过以 Instrcution 为指导的大量任务进行学习,提升在未知任务的性能。
首先我们介绍下 Instruction Tuning 与之前比较火的 Prompt tuning 方法的区别。
Prompt tuning:针对每个任务,单独生成 prompt 模板(hard prompt or soft prompt),然后在每个任务上进行 full-shot 微调与评估,其中预训练模型参数是 freeze 的。
在此说明下 prompt 方法的发展思路,一开始大家通过完形填空的方式发掘语言模型的能力,在 few-shot 上获取比较好的效果,因为完形填空更符合预训练的形式,后面 p-tuning 提出连续的 token,但是还是依赖 hard token 作为初始化,并且比较敏感,也是在 full-shot 上证明了 prompt 方法比传统的 finetune 好,之前大家更多关注的是 few-shot 上的效果,后面出了很多花式魔改相关的论文,比如给 Verbalizer 融合知识或者直接去掉什么的,这里就不过多介绍了。
注意:在这之前预训练模型都是跟着一起训练的!后面谷歌的 prompt tuning 诞生,在 T5 上通过 freeze 预训练模型,只调添加在第一层的 soft prompt,在 full-shot 上就能和 finetune 上效果相当,这样新坑出现了,后面出了一系统工作,比如 PPT、P-tuning v2 和 SPoT 等,这里也不详细介绍了。
其实 prompt tuning 之前早就有类似的工作 prefix tuning,和 prompt tuning 区别是在每层都添加 soft token,只不过当时 prompt 还没火,现在火了提出了新的概念 prompt tuning,现在的 prompt tuning 的一系列方法和 adapter 越来越像了,感觉违背之前 prompt 发展初期 hard prompt 的初衷,这种 soft prompt 没有像 hard prompt 那种直接激发预训练模型的能力,所以在 few-shot 上通过 freeze 预训练模型微调 prompt 效果不好也可以理解。
后面 ICLR 高分论文 Towards a Unified View of Parameter-Efficient Transfer Learning 把 prompt tuning、adapter 和 LoRA 这些 Parameter-Efficient 方法都统一起来了,大家有兴趣可以自己去看。
Instruction Tuning:针对每个任务,单独生成 instruction(hard token),通过在若干个 full-shot 任务上进行微调,然后在具体的任务上进行评估泛化能力(zero shot),其中预训练模型参数是 unfreeze 的。Instruction Tuning 和 Prompt 方法的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于,Prompt 是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做 language model 任务,而 Instruction Tuning 则是激发语言模型的理解能力,通过给出更明显的指令,让模型去理解并做出正确的反馈。

FLAN

论文链接:
1.1 Motivation
本文提出一种基于 instruction-tuning 的方法叫做 FLAN,一种通过提升语言模型对 instructions 的理解能力从而提高语言模型零样本学习能力的简单方法。
Method:
a. 训练模型:137B 规模的 decoder-only LM---LaMDA-PT
b. 数据集:一共 62 个的 NLP task,根据任务类别进行分类,例如 Natural language inference、Machine translation 和 Sentiment 等,为了增加多样性对于每个任务 10 个手动构建 10 个 template。
c. 评估方法:例如当评估 Natural language inference 时候,把所有属于 Natural language inference 从训练集中剔除。当做生成任务时候直接用语言模型生成目标结果,当做分类时候,设置了一个 options suffix 选项后缀,将所有的分类结果通过 OPTIONS:拼在样本后面。fews-shot 场景使用 packing 将多个训练示例组合成一个序列,使用特殊的 EOS 将输入与目标分离。
d. 训练方法:混合所有数据集,并从每个数据集中随机抽取样本,为了平衡不同大小的数据集,将每个数据集的训练示例数限制为 30k,并遵循示例比例混合方案,最大混合率为 3k。一共训练 30k steps,输入最大长度为 1024,输出最大长度为 256。
1.2 Contribution
在 25 个数据集中的 20 个上超过了零样本学习的 175B GPT-3,甚至在 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze 上都远远优于 few-shot 小样本学习的 GPT-3。实验表明任务的聚类数量增加、模型规模增大和 instruction 都对模型的 zero-shot 能力有促进作用,这些因素也比较符合直觉,并且激发了对通用模型的进一步研究。
但是 instruction tuning 虽然对于自然表述为指令的任务(例如 NLI、QA、翻译等)非常有效,而对于直接表述为语言建模的任务(Natural language inference等)则不太有效,可能和 NLI 样例不太可能在无监督的训练集中自然出现有关系。

T0

论文链接:
2.1 Motivation
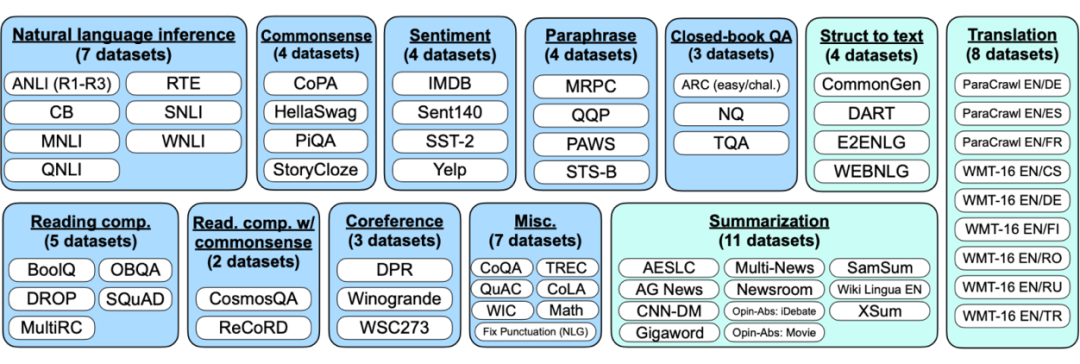
T0 和 FLAN 工作整体相似,区别是增加了任务和 prompt 数量,FLAN 使用了 decoder-only,T0 使用了 encoder+decoder,FLAN 每次针对测试一个任务训练一个模型,其他任务作为训练集,T0 为了测试模型泛化能力,只在多任务数据集上训练一个模型。证明了隐式多任务学习能提升模型泛化和 zero-shot 能力。
2.2 Method
a. 训练模型:11B LM-adapted T5 model---T5+LM
b. 数据集:一共 171 个多任务数据集,总共创建了 1939 个 prompt,平均每个数据集有 11.3 个 prompt,共有来自 8 个国家、24 家机构的 36 位人员贡献 prompt。Prompt 开发地址:
c. 评估方法:人工划分训练和测试集,Multiple-Choice QA、Summarization 和Topic Classification等作为训练集,4 个传统的 nlp 任务 natural language inference、coreference、word sense disambiguation、sentence completion 和 14 个来自 BIG-bench 作为测试集,使用 accuracy 作为评估指标,和 FLAN 比没有做 few-shot 相关的实验。
d. 训练方法:对样本超过 50k 的数据集,采样 500000 / num templates 样本,其中 num templates 为数据集的 template 数量。学习率为 1e-3,输入最大长度为 1024,输出最大长度为 256。
2.3 Contribution
T0 与 GPT-3 的 Zero-shot 性能对比,T0 模型在 11 个数据上中有 8 个超越了GPT-3,而 T0 模型比 GPT-3 比小 160 倍,增加更多的 prompt 数量,会提升 Zero-Shot 泛化性能。相比 FLAN 模型参数减少超过 10 倍,在 zero-shot 场景下效果 CB 和 RTE 超过 FLAN,Winogrande 和 ANLI 比 FLAN 稍差。

InstructGPT

论文链接:
3.1 Motivation
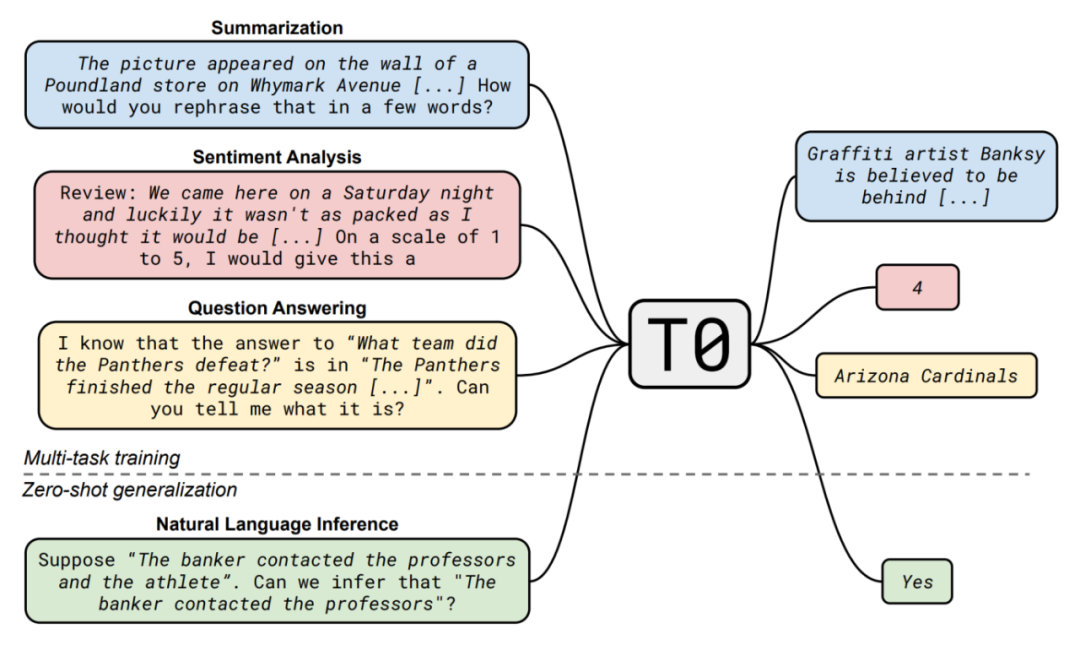
使用一种通过人类反馈的强化学习(RLHF)技术,根据用户和 API 的交互结果,对模型的多个输出进行了排名,然后再利用这些数据微调 GPT-3,使得 InstructGPT 模型在遵循指令方面比 GPT-3 更好。
3.2 Method
a. 训练模型:1.3B GPT3
b. 数据集:收集人类标注演示数据集用于训练模型,同时收集了一个多模型生成的标注演示数据集,在更大的 API 提示集上对多个模型的输出进行比较,用于训练强化学习的 Reward。
c. 评估方法:使用强化学习 Reward 对模型输出结果进行评估。
d. 训练方法:使用 Reward 作为奖励函数,来微调 GPT-3 策略,使用 PPO 算法最大化这个奖励。
3.3 Contribution
虽然参数少了 100 倍以上,InstructGPT 的输出结果比 GPT-3 以及用监督学习进行微调的模型都要高得多。与 GPT-3 相比,InstructGPT 产生的错误较少,安全性更高。同时还对模型的提示分布进行了人类评估,结果显示,InstructGPT 编造事实的情况较少,而且产生的输出结果更合适。此外,InstructGPT 的输出比 FLAN 和 T0 的输出要好,提供了提供模型泛化能力新思路。

Natural-Instructions v2

论文链接:
4.1 Motivation
提出 NATURAL-INSTRUCTIONSv2 新的评估模型泛化能力 Benchmark,涵盖了 1600+ 个任务、70+ 个不同任务类型、50+ 种不同语言,和 FLAN 不同的是使用了 in-context learning。
4.2 Method
a. 训练模型:3B T5
b. 数据集:1616 个 task,76 个 task 类型,16 种推理类型, 非英文任务有 576 个,每个任务平均有 3k+ 个样本。这些任务是由 88 位人员从 GitHub 社区收集来的,覆盖了业界已公布的数据以及新构造的任务,并且添加了详尽的任务介绍,已确保满足读者的需求。其中包括机器翻译、QA,文本分类等任务类型,英语、西班牙语、日语等语种,涉及新闻、对话、数学等多个领域学科,可见其丰富程度。分成了验证集合和训练集合两个子集,一个用于评估,一个用于监督训练。其中人工挑选的验证集合包括 12 个类别 154 个任务,其中 119 个英文任务,35 个跨语种任务。每个任务选出 100 个随机实例用来评估,增加了 Explanation。
c. 评估方法:在评估指标上,选用文本生成中广泛使用的 ROUGE-L,除此之外,对于输出较短且有限的任务,还引入了 Exact Match,衡量模型推理出的字符串和标准输出完全匹配的比率,其中主要评估 english 和 x-lingual 两大类数据集。
d. 训练方法:使用 in-context learning,Tk-INSTRUCT 其中 k 代表示例的数量,k=2 代表 2 个示例。训练 2 个 epoch,输入最大长度设置为 1024,输出设置为 128,学习率采用 1e-5。
4.3 Contribution
在新的 benchmark 上比 T5、GPT3、T0 和 GPT3-Instruct 效果好,其中实验表明更多任务和模型规模增大有利于模型泛化提升,而每个任务数量和更多的 examples 并没有帮助模型泛化提升,负样例对效果有一点提升。


总结
如果模型缺乏泛化能力,那么模型表现的上限只能是已经见到过的数据,会经常出现在 Task A 的 sota 模型,换到相似的 Task B 上可能就没有那么 Work 了,尽管大模型有着惊人的分布内泛化能力,但是分布外泛化仍是这些模型最关键最难以解决的问题,Instruction Tuning 可能是未来缓解这个问题的一种解决方案,目前 Instruction Tuning 比较一致的实验结论是随着训练任务的数量、instruction 数量和模型规模增大,泛化效果越好,相信随着任务、模型参数不断扩大,能激发对通用模型的进一步研究。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



