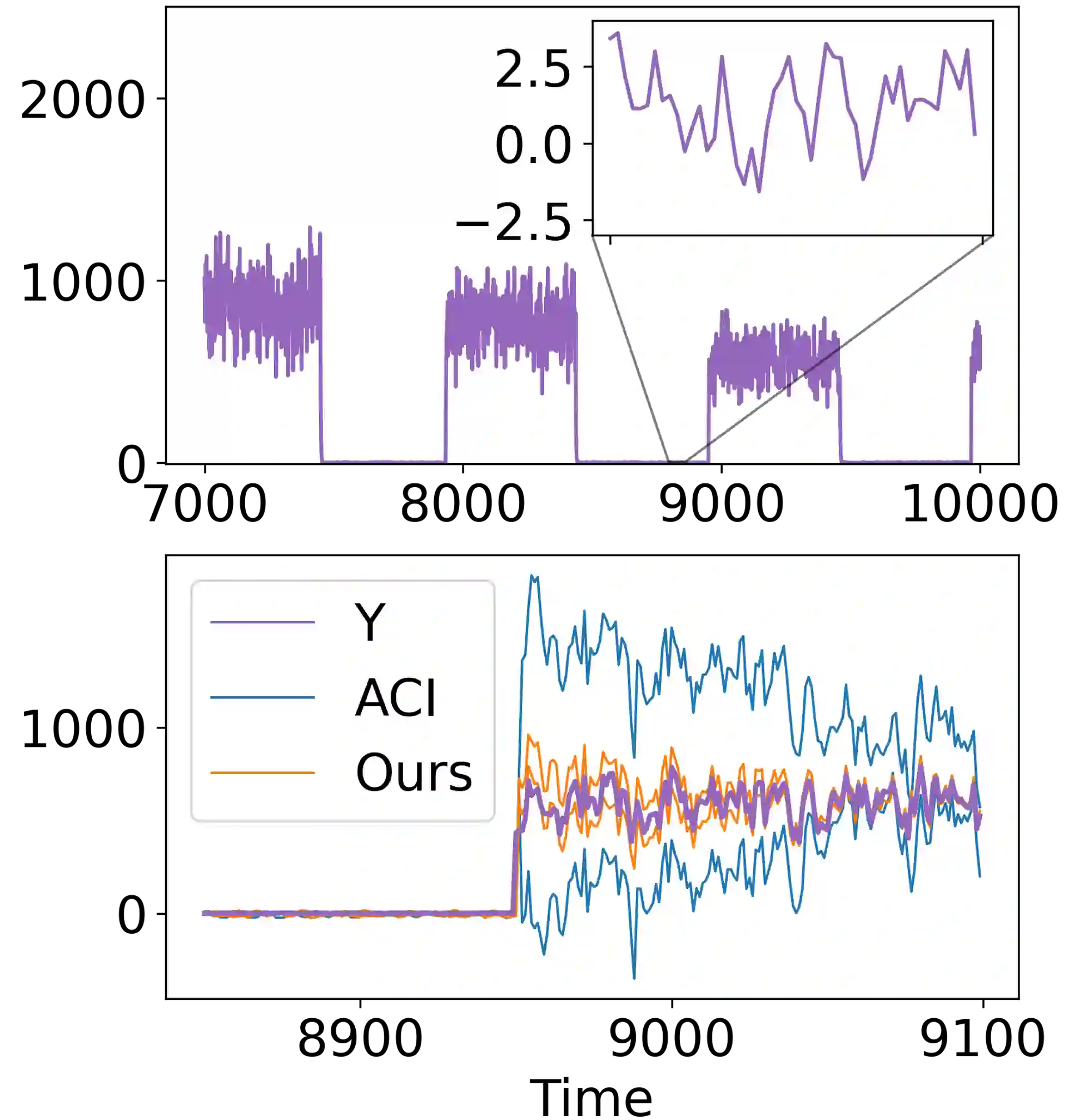
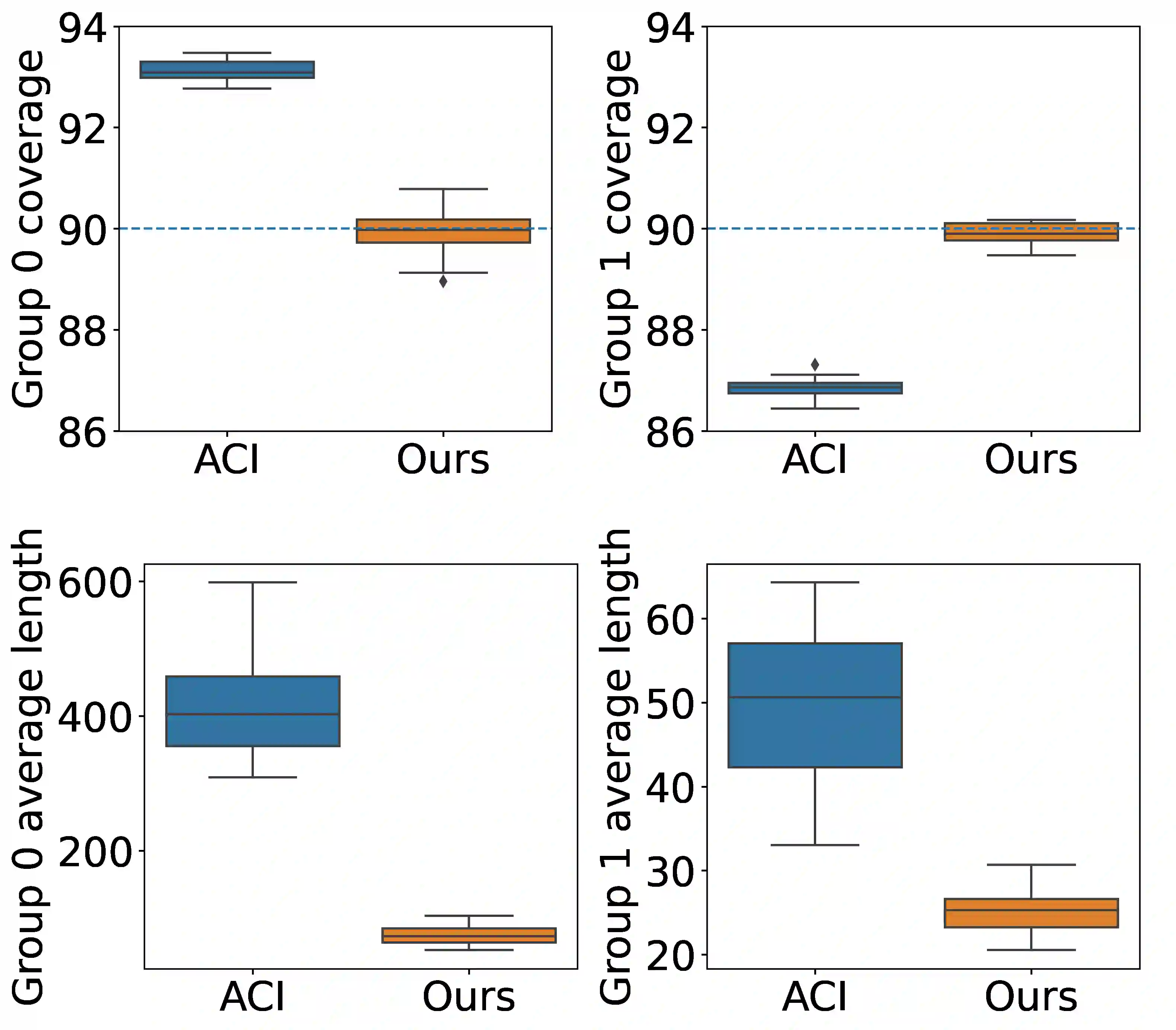
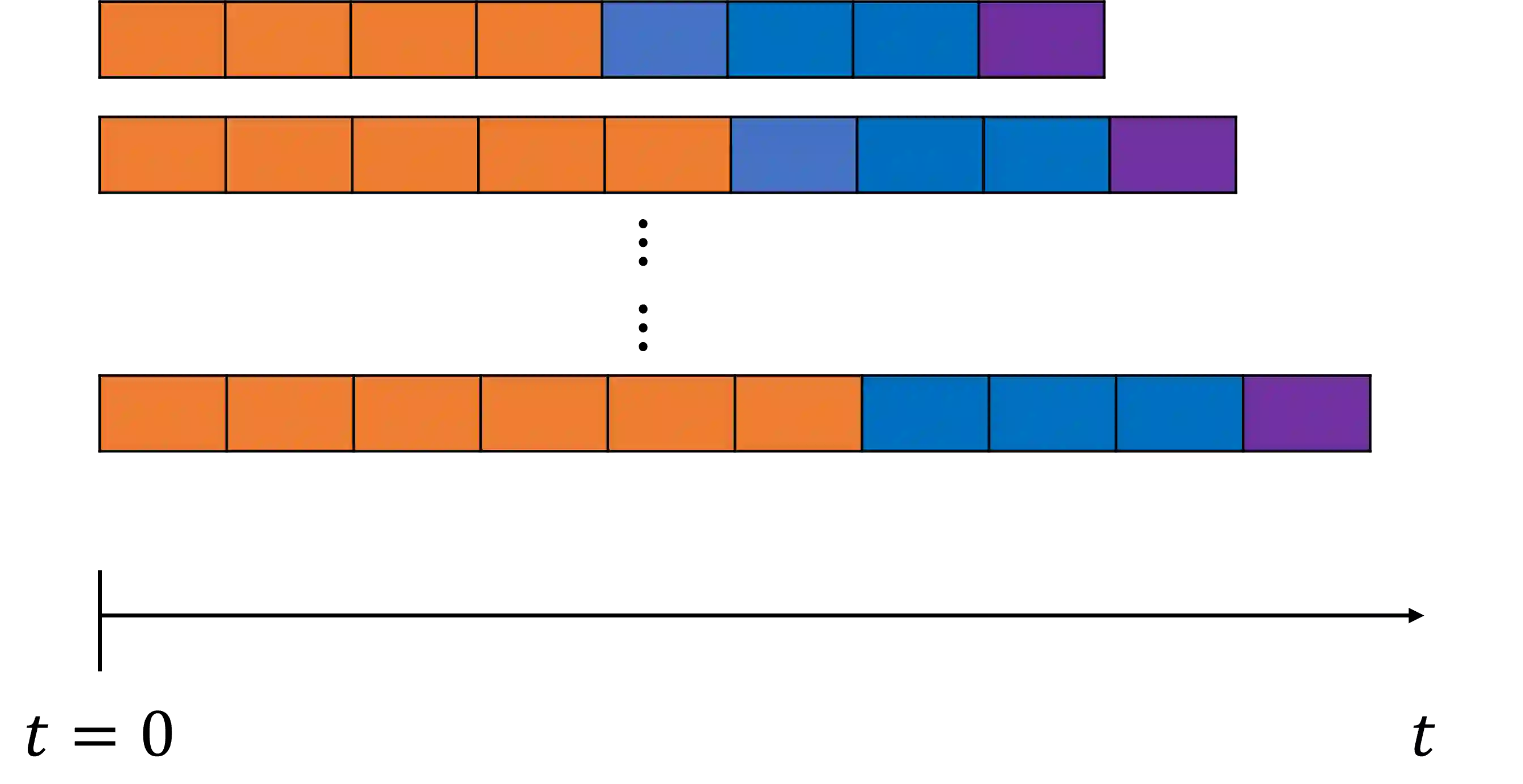
We develop a framework for constructing uncertainty sets with a valid coverage guarantee in an online setting, in which the underlying data distribution can drastically -- and even adversarially -- shift over time. The technique we propose is highly flexible as it can be integrated with any online learning algorithm, requiring minimal implementation effort and computational cost. A key advantage of our method over existing alternatives -- which also build on conformal inference -- is that we do not need to split the data into training and holdout calibration sets. This allows us to fit the predictive model in a fully online manner, utilizing the most recent observation for constructing calibrated uncertainty sets. Consequently, and in contrast with existing techniques, (i) the sets we build can quickly adapt to new changes in the distribution; and (ii) our procedure does not require refitting the model at each time step. Using synthetic and real-world benchmark data sets, we demonstrate the validity of our theory and the improved performance of our proposal over existing techniques. To demonstrate the greater flexibility of the proposed method, we show how to construct valid intervals for a multiple-output regression problem that previous sequential calibration methods cannot handle due to impractical computational and memory requirements.
翻译:我们开发了一个框架,用于构建不确定性数据集,在网上环境下提供有效的覆盖保障,使基础数据分布能够随时间推移而发生急剧变化,甚至对抗性的变化。我们提出的技术非常灵活,因为它可以与任何在线学习算法相结合,需要最低限度的实施努力和计算成本。我们的方法相对于现有替代方法(同时也以一致推理为基础)的一个重要优势是,我们不需要将数据分成培训和坚持校准组合,这样我们就能够完全在线地适应预测模型,利用最新观测数据构建校准的不确定性数据集。因此,与现有技术相反,(一) 我们所建造的数据集可以快速适应分配中的新变化;以及(二) 我们的程序并不要求每步都对模型进行调整。我们使用合成和现实世界基准数据集,展示我们理论的有效性和我们提案对现有技术的改进性。为了展示拟议方法的更大灵活性,我们展示了如何为先前的顺序校准方法无法处理的多输出回归问题构建有效间隔,而先前的校准方法由于不切实际的计算和记忆要求而不能处理的问题。