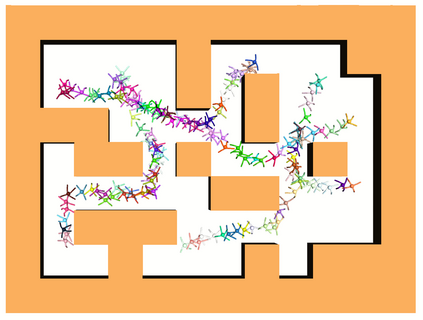
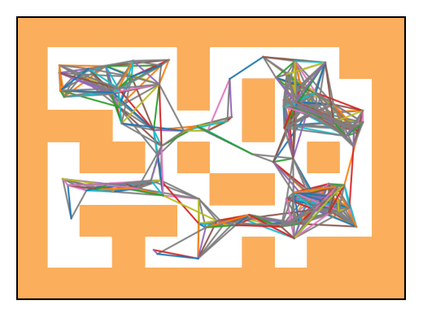
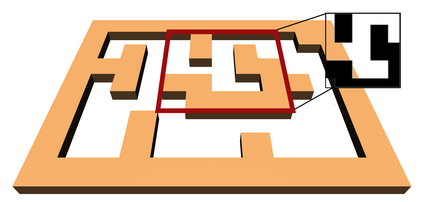
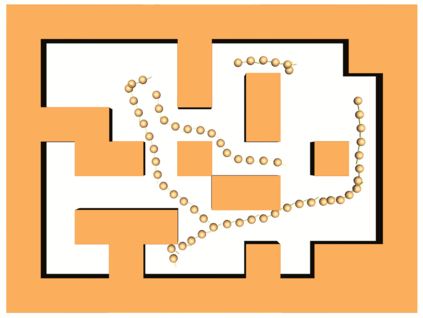
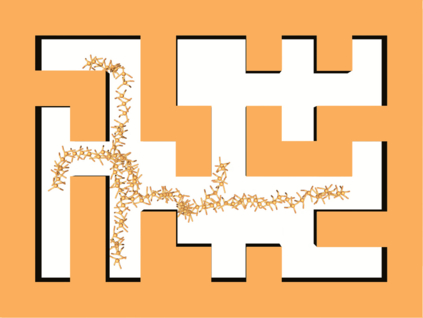
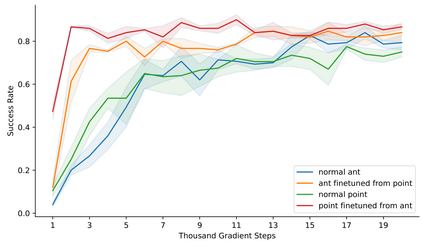
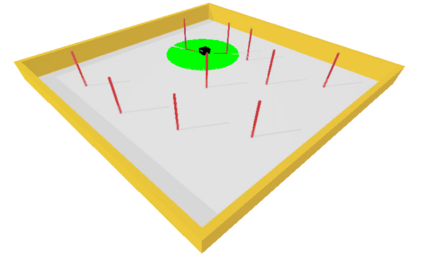
Learning long-horizon tasks such as navigation has presented difficult challenges for successfully applying reinforcement learning. However, from another perspective, under a known environment model, methods such as sampling-based planning can robustly find collision-free paths in environments without learning. In this work, we propose Control Transformer which models return-conditioned sequences from low-level policies guided by a sampling-based Probabilistic Roadmap (PRM) planner. Once trained, we demonstrate that our framework can solve long-horizon navigation tasks using only local information. We evaluate our approach on partially-observed maze navigation with MuJoCo robots, including Ant, Point, and Humanoid, and show that Control Transformer can successfully navigate large mazes and generalize to new, unknown environments. Additionally, we apply our method to a differential drive robot (Turtlebot3) and show zero-shot sim2real transfer under noisy observations.
翻译:诸如导航等学习长视线任务对成功应用强化学习提出了困难的挑战。然而,从另一个角度看,根据已知的环境模型,抽样规划等方法可以在不学习的情况下在环境中强有力地找到无碰撞路径。在这项工作中,我们提议控制变异器,该变异器在基于取样的概率性路线图(PRM)规划师的指导下,从低层次的政策中模拟有回归条件的序列。经过培训后,我们证明我们的框架仅使用当地信息就能解决长视线导航任务。我们评估了我们与包括Ant、Point和人类类人在内的穆乔科机器人进行部分观测的迷宫导航的方法,并表明控制变异器能够成功导航大型迷宫,并概括到新的、未知的环境。此外,我们将我们的方法应用到一个有差异的驱动器(Turtetlebot3),并显示在噪音观测下零发的Sim2真实传输。