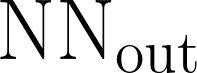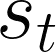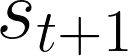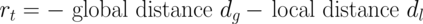Developing agents that can execute multiple skills by learning from pre-collected datasets is an important problem in robotics, where online interaction with the environment is extremely time-consuming. Moreover, manually designing reward functions for every single desired skill is prohibitive. Prior works targeted these challenges by learning goal-conditioned policies from offline datasets without manually specified rewards, through hindsight relabelling. These methods suffer from the issue of sparsity of rewards, and fail at long-horizon tasks. In this work, we propose a novel self-supervised learning phase on the pre-collected dataset to understand the structure and the dynamics of the model, and shape a dense reward function for learning policies offline. We evaluate our method on three continuous control tasks, and show that our model significantly outperforms existing approaches, especially on tasks that involve long-term planning.
翻译:通过从预先收集的数据集中学习可以执行多种技能的发展代理物是机器人的一个重要问题,因为在那里,与环境的在线互动极其耗时。此外,手工设计每种理想技能的奖励功能是令人望而却步的。 先前的工作通过事后的重新标签,通过不使用手工指定的奖励而学习离线数据集的有目标限制的政策,来应对这些挑战。这些方法存在奖励的广度问题,并且无法完成长期横向任务。在这项工作中,我们提议在预先收集的数据集上建立一个新的自我监督学习阶段,以了解模型的结构和动态,并为离线学习政策塑造一个密集的奖励功能。我们在三项连续控制任务上评估我们的方法,并显示我们的模型大大优于现有方法,特别是在涉及长期规划的任务上。