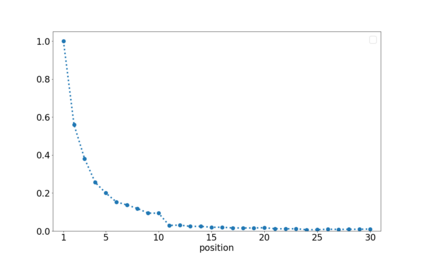
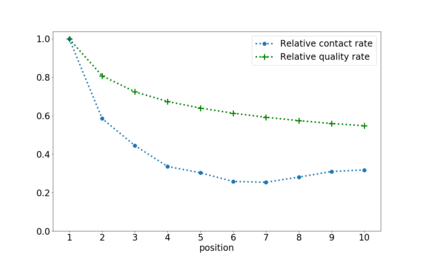
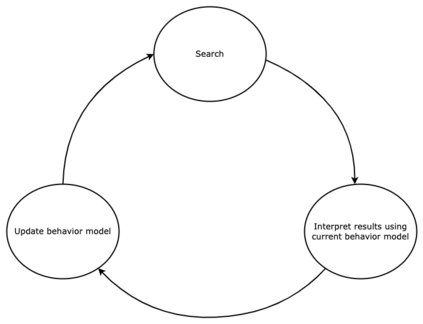
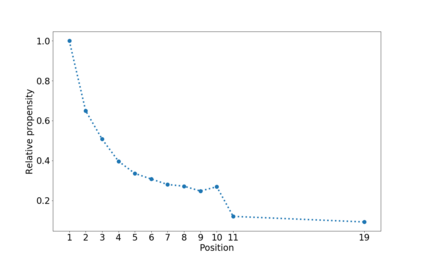
Search engines intentionally influence user behavior by picking and ranking the list of results. Users engage with the highest results both because of their prominent placement and because they are typically the most relevant documents. Search engine ranking algorithms need to identify relevance while incorporating the influence of the search engine itself. This paper describes our efforts at Thumbtack to understand the impact of ranking, including the empirical results of a randomization program. In the context of a consumer marketplace we discuss practical details of model choice, experiment design, bias calculation, and machine learning model adaptation. We include a novel discussion of how ranking bias may not only affect labels, but also model features. The randomization program led to improved models, motivated internal scenario analysis, and enabled user-facing scenario tooling.
翻译:搜索引擎有意通过选择和排列结果列表来影响用户行为。 用户因其突出的位置和通常是最相关的文档而接触最高的结果。 搜索引擎排名算法需要识别相关性,同时纳入搜索引擎本身的影响。 本文描述了我们在Tumbtack为理解排名影响所做的努力, 包括随机化程序的经验结果。 在消费市场的背景下, 我们讨论模型选择、 实验设计、 偏差计算和机器学习模型适应的实用细节。 我们包括了一次新颖的讨论, 讨论排名偏差如何不仅影响标签, 而且还影响模型特征。 随机化程序导致改进模型、 动机性内部情景分析, 并允许用户配置情景工具 。