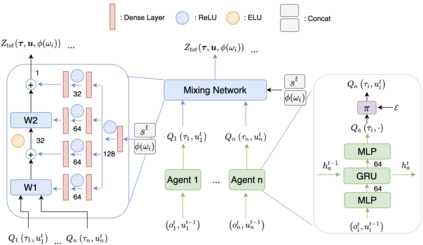
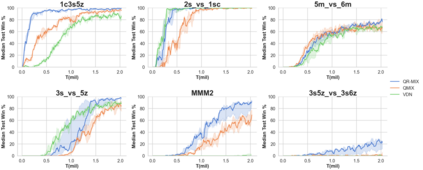
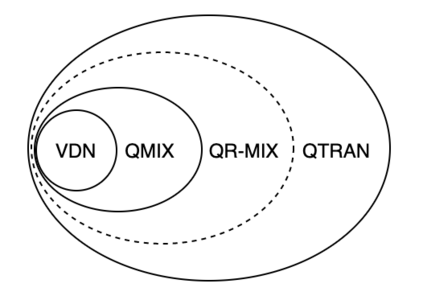
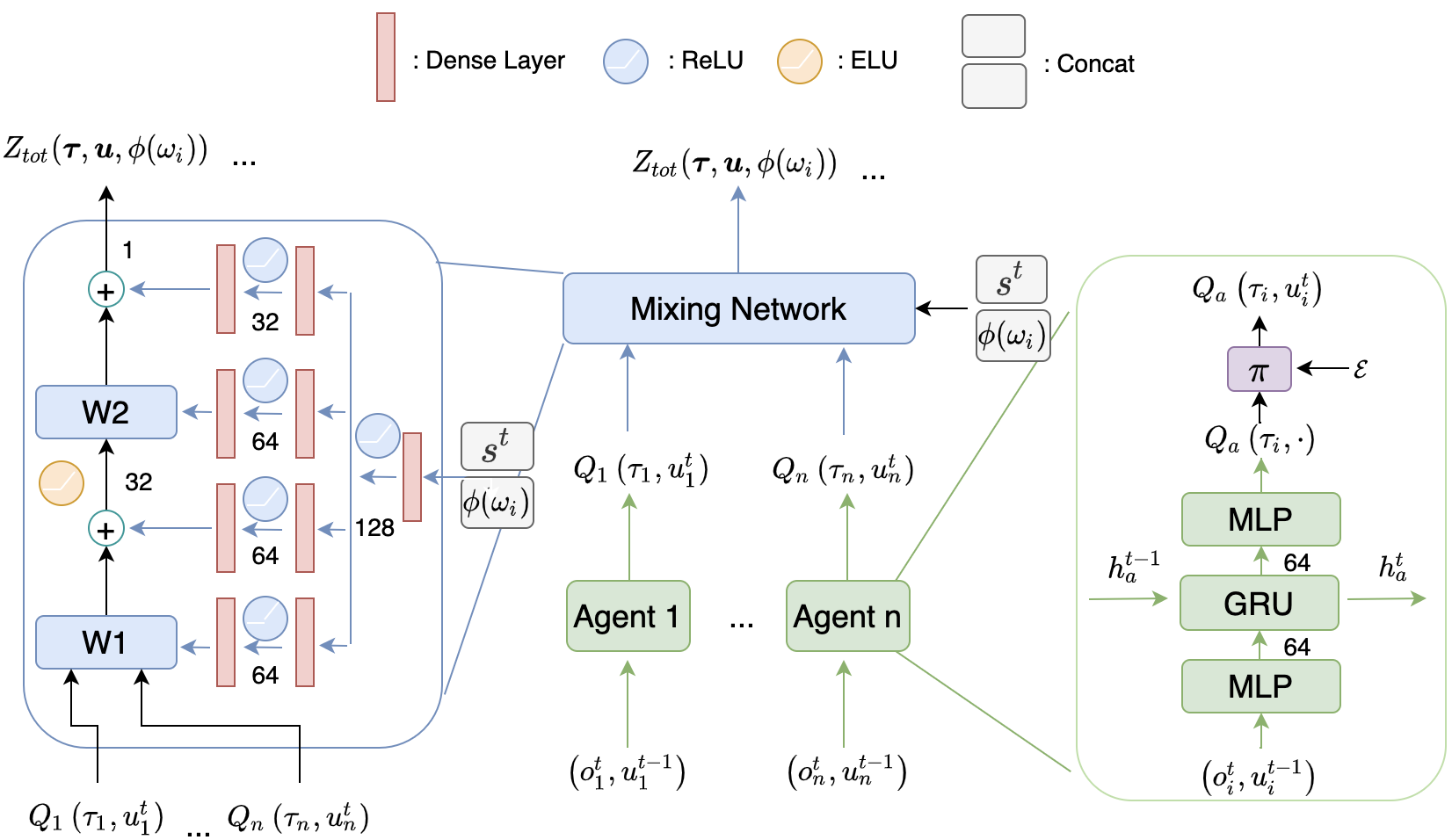
In Cooperative Multi-Agent Reinforcement Learning (MARL) and under the setting of Centralized Training with Decentralized Execution (CTDE), agents observe and interact with their environment locally and independently. With local observation and random sampling, the randomness in rewards and observations leads to randomness in long-term returns. Existing methods such as Value Decomposition Network (VDN) and QMIX estimate the value of long-term returns as a scalar that does not contain the information of randomness. Our proposed model QR-MIX introduces quantile regression, modeling joint state-action values as a distribution, combining QMIX with Implicit Quantile Network (IQN). However, the monotonicity in QMIX limits the expression of joint state-action value distribution and may lead to incorrect estimation results in non-monotonic cases. Therefore, we proposed a flexible loss function to approximate the monotonicity found in QMIX. Our model is not only more tolerant of the randomness of returns, but also more tolerant of the randomness of monotonic constraints. The experimental results demonstrate that QR-MIX outperforms the previous state-of-the-art method QMIX in the StarCraft Multi-Agent Challenge (SMAC) environment.
翻译:在合作性多点强化学习(MARL)中和在集中培训与分散执行(CTDE)的设置下,代理商在当地和独立地观察并与其环境互动。通过当地观察和随机抽样,奖励和观察随机性导致长期回报随机性。现有的方法,如价值分解网络(VDN)和 QMIX 估计长期回报值是一个不包含随机性信息的标度值。我们提议的模型 QR- MIX 引入了量化回归,将联合州行动值作为分布模型,将 QMIX 与隐性量子网络(IQN)相结合。然而, QMIX 的单一性限制了联合州-行动值分布的表达方式,可能导致不正确估计非分子案件的结果。因此,我们提议了一种灵活的损失功能,以近似QMIX 中发现的单项性。我们的模型不仅更容误,而且更容容性也更容性地反映了单项制约的随机性,同时将QM-QIX 与隐性网络(IN) 的随机性。实验结果显示,前一个挑战-C-C-Star-C-C-C-C-Star-C-SDA 格式环境。