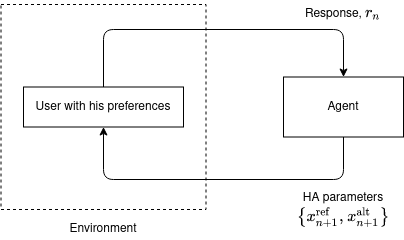
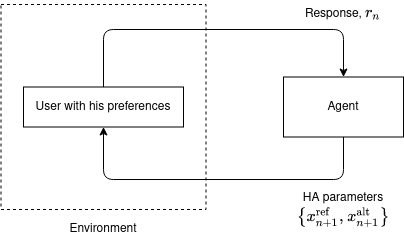
In this work, we study the problem of user preference learning on the example of parameter setting for a hearing aid (HA). We propose to use an agent that interacts with a HA user, in order to collect the most informative data, and learns user preferences for HA parameter settings, based on these data. We model the HA system as two interacting sub-systems, one representing a user with his/her preferences and another one representing an agent. In this system, the user responses to HA settings, proposed by the agent. In our user model, the responses are driven by a parametric user preference function. The agent comprises the sequential mechanisms for user model inference and HA parameter proposal generation. To infer the user model (preference function), Bayesian approximate inference is used in the agent. Here we propose the normalized weighted Kullback-Leibler (KL) divergence between true and agent-assigned predictive user response distributions as a metric to assess the quality of learned preferences. Moreover, our agent strategy for generating HA parameter proposals is to generate HA settings, responses to which help resolving uncertainty associated with prediction of the user responses the most. The resulting data, consequently, allows for efficient user model learning. The normalized weighted KL-divergence plays an important role here as well, since it characterizes the informativeness of the data to be used for probing the user. The efficiency of our approach is validated by numerical simulations.
翻译:在这项工作中,我们研究用户偏好学习助听器(HA)参数设置示例的问题。我们建议使用一个与HA用户互动的代理商,以便收集信息量最高的数据,并学习用户根据这些数据对HA参数设置的偏好。我们将HA系统建模为两个互动子系统,一个代表用户的偏好,另一个代表代理商的代理商。在这个系统中,用户对HA设置的反应是由代理商提议的。在我们的用户模型中,用户对HA设置的反应是由用户偏好功能驱动的。代理商包括用户模型推断和HA参数建议生成的相继机制。为了推断用户模型(参考功能),Bayesian 近似推论在代理商中使用了HA参数设置的首选。我们在这里建议将URB-Leiber (KL) 系统建模加权加权加权的用户响应分布作为评估所学到的偏好选择的质量的衡量标准。此外,我们生成HA参数的代理商策略是生成HA设置,对于帮助解决用户预测用户反应的不确定性的模型(参考功能功能),由此而使数据成为了正常的基化的模型,因此,使数据成为了一种有效的数据成为了这里的典型用户的典型的典型的典型的典型。 学习。因此,因此,使数据成为了一种有效的数据成为了一种有效的数据成为了一种有效的数据, 的典型的典型的典型的典型。