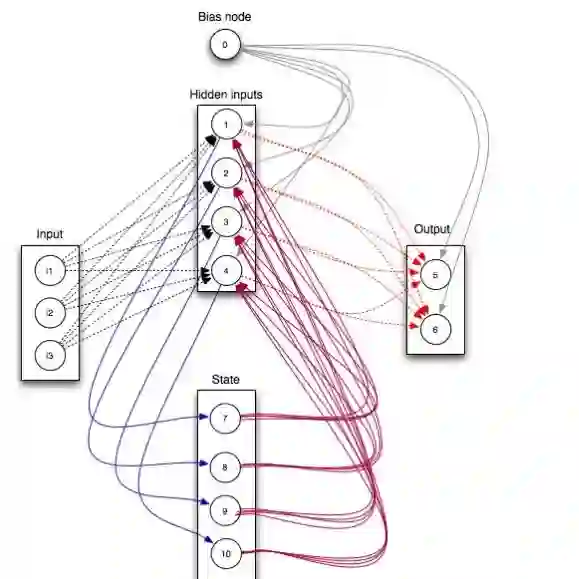
Training Restricted Boltzmann Machines (RBMs) has been challenging for a long time due to the difficulty of computing precisely the log-likelihood gradient. Over the past decades, many works have proposed more or less successful training recipes but without studying the crucial quantity of the problem: the mixing time i.e. the number of Monte Carlo iterations needed to sample new configurations from a model. In this work, we show that this mixing time plays a crucial role in the dynamics and stability of the trained model, and that RBMs operate in two well-defined regimes, namely equilibrium and out-of-equilibrium, depending on the interplay between this mixing time of the model and the number of steps, $k$, used to approximate the gradient. We further show empirically that this mixing time increases with the learning, which often implies a transition from one regime to another as soon as $k$ becomes smaller than this time. In particular, we show that using the popular $k$ (persistent) contrastive divergence approaches, with $k$ small, the dynamics of the learned model are extremely slow and often dominated by strong out-of-equilibrium effects. On the contrary, RBMs trained in equilibrium display faster dynamics, and a smooth convergence to dataset-like configurations during the sampling. Finally we discuss how to exploit in practice both regimes depending on the task one aims to fulfill: (i) short $k$s can be used to generate convincing samples in short times, (ii) large $k$ (or increasingly large) must be used to learn the correct equilibrium distribution of the RBM.
翻译:培训限制的 Boltzmann 机器( RBMS) 长期以来一直具有挑战性, 原因是很难精确计算日志相似度梯度。 在过去几十年里, 许多工程都提出了多少或更少的成功培训配方, 但没有研究问题的关键数量: 混合时间, 即从模型中抽取新配置样本所需的蒙特卡洛迭代次数。 在这项工作中, 我们显示, 这种混合时间在经过培训的模式的动态和稳定性中发挥着关键作用, 并且成果管理制在两种定义明确的制度下运作, 即平衡和不均匀, 取决于模型的平衡分配时间和用于接近梯度的步骤数量之间的相互作用。 我们从经验上进一步表明, 混合时间会随着学习时间的混合而增加, 这往往意味着当美元比这个模式小的时候, 混合时间会在经过培训的短期美元( 可见的) 对比性差异化方法, 也就是低价廉, 学习的模型的动态必须非常缓慢, 并且往往以强烈的超正比的汇率方法为主 。 在经过培训的大幅的汇率上,, 快速地, 快速地, 学习 。