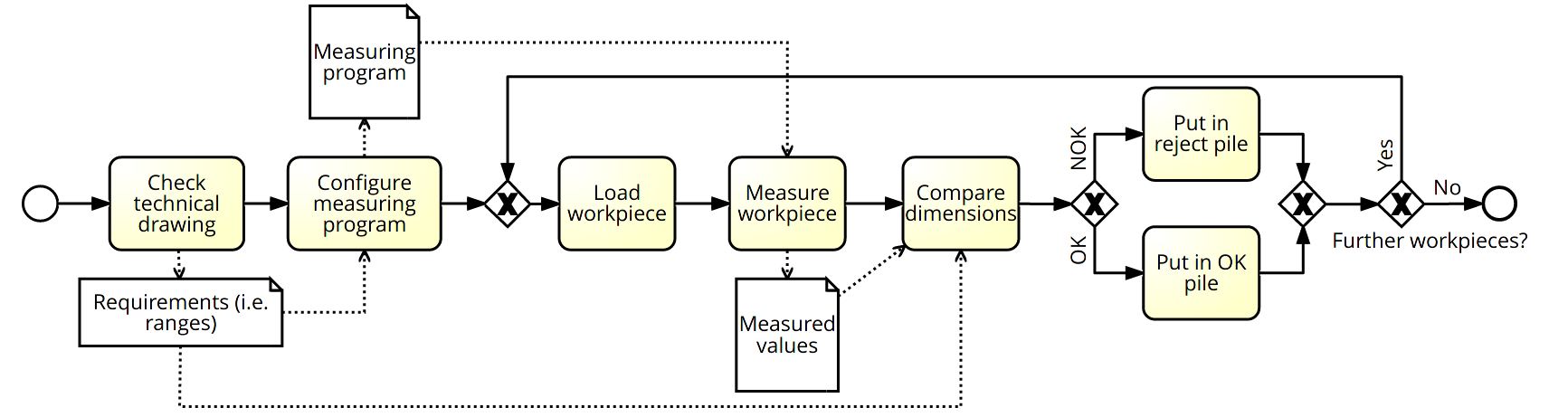
Decisions and the underlying rules are indispensable for driving process execution during runtime, i.e., for routing process instances at alternative branches based on the values of process data. Decision rules can comprise unary data conditions, e.g., age > 40, binary data conditions where the relation between two or more variables is relevant, e.g. temperature1 < temperature2, and more complex conditions that refer to, for example, parts of a medical image. Decision discovery aims at automatically deriving decision rules from process event logs. Existing approaches focus on the discovery of unary, or in some instances binary data conditions. The discovered decision rules are usually evaluated using accuracy, but not with regards to their semantics and meaningfulness, although this is crucial for validation and the subsequent implementation/adaptation of the decision rules. Hence, this paper compares three decision mining approaches, i.e., two existing ones and one newly described approach, with respect to the meaningfulness of their results. For comparison, we use one synthetic data set for a realistic manufacturing case and the two real-world BPIC 2017/2020 logs. The discovered rules are discussed with regards to their semantics and meaningfulness.
翻译:决定规则和基本规则对于运行期间驱动流程执行必不可少,即对于基于流程数据值的替代分支的路径处理过程情况,决定规则可以包括单数据条件,例如年龄 > 40, 两个或两个以上变量之间的关系相关的二元数据条件,例如温度1 < 温度2, 以及更复杂的条件,例如医疗图像的某些部分; 决定发现的目的是从流程事件日志中自动得出决定规则; 现有方法侧重于发现单数,或在某些情况下是二元数据条件; 发现的决定规则通常使用准确性来评估,但并不涉及其语义和意义,尽管这对于验证和随后执行/调整决定规则至关重要; 因此,本文件比较了三项决定采矿方法,即两个现有方法和一个新描述的方法,其结果是否有意义; 为了比较,我们使用一套合成数据集,用于现实的制造案例和两个真实世界BPIC 2017/2020日日日志。 所发现的规则讨论的是其真实性和意义。