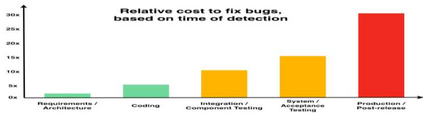
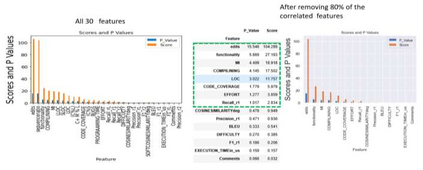
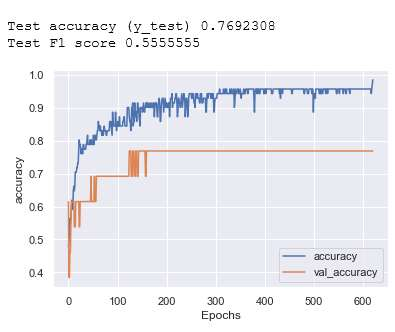
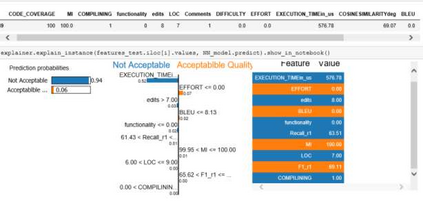
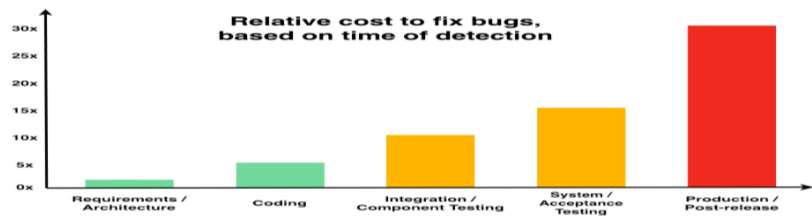
Today, AI technology is showing its strengths in almost every industry and walks of life. From text generation, text summarization, chatbots, NLP is being used widely. One such paradigm is automatic code generation. An AI could be generating anything; hence the output space is unconstrained. A self-driving car is driven for 100 million miles to validate its safety, but tests cannot be written to monitor and cover an unconstrained space. One of the solutions to validate AI-generated content is to constrain the problem and convert it from abstract to realistic, and this can be accomplished by either validating the unconstrained algorithm using theoretical proofs or by using Monte-Carlo simulation methods. In this case, we use the latter approach to test/validate a statistically significant number of samples. This hypothesis of validating the AI-generated code is the main motive of this work and to know if AI-generated code is reliable, a metric model CGEMs is proposed. This is an extremely challenging task as programs can have different logic with different naming conventions, but the metrics must capture the structure and logic of the program. This is similar to the importance grammar carries in AI-based text generation, Q&A, translations, etc. The various metrics that are garnered in this work to support the evaluation of generated code are as follows: Compilation, NL description to logic conversion, number of edits needed, some of the commonly used static-code metrics and NLP metrics. These metrics are applied to 80 codes generated using OpenAI's GPT-3. Post which a Neural network is designed for binary classification (acceptable/not acceptable quality of the generated code). The inputs to this network are the values of the features obtained from the metrics. The model achieves a classification accuracy of 76.92% and an F1 score of 55.56%. XAI is augmented for model interpretability.
翻译:今天, AI 技术正在几乎每个行业和生活行各行各行各业展示其优势。 从文本生成、 文本总和、 聊天机、 NLP 正在被广泛使用。 其中一个范例是自动代码生成。 AI 可能会产生任何东西; 因此输出空间不受限制。 驱动一亿英里的自驾汽车可以验证其安全性, 但测试不能用来监控和覆盖一个不受限制的空间。 验证 AI 生成的内容的解决方案之一是限制问题, 并将它从抽象的版本转换为现实化, 而这可以通过使用理论校对或蒙特- 卡洛模拟方法验证未受限制的算法。 其中一个范例就是自动生成代码。 使用后一种方法测试/ 任何具有统计意义的样本。 校验的自动代码是自动码, 使用自动码的自动代码是自动的代碼, 使用自动的自动碼是自动的代碼, 以自动的代碼是自动的代碼, 代碼是自动的代碼, 代碼是自动的代碼, 代碼是自动的自动的自动的自动的代碼。 代碼是自动的自動的自動的代碼, 自动的自動的自動的自動的自動的代碼, 自動的自動的自動的自動的自動的自動的自動的自動的自動的自動的數數數數數的數的代碼, 。