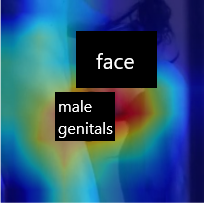
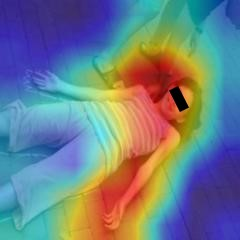
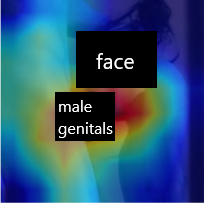
The sheer volume of online user-generated content has rendered content moderation technologies essential in order to protect digital platform audiences from content that may cause anxiety, worry, or concern. Despite the efforts towards developing automated solutions to tackle this problem, creating accurate models remains challenging due to the lack of adequate task-specific training data. The fact that manually annotating such data is a highly demanding procedure that could severely affect the annotators' emotional well-being is directly related to the latter limitation. In this paper, we propose the CM-Refinery framework that leverages large-scale multimedia datasets to automatically extend initial training datasets with hard examples that can refine content moderation models, while significantly reducing the involvement of human annotators. We apply our method on two model adaptation strategies designed with respect to the different challenges observed while collecting data, i.e. lack of (i) task-specific negative data or (ii) both positive and negative data. Additionally, we introduce a diversity criterion applied to the data collection process that further enhances the generalization performance of the refined models. The proposed method is evaluated on the Not Safe for Work (NSFW) and disturbing content detection tasks on benchmark datasets achieving 1.32% and 1.94% accuracy improvements compared to the state of the art, respectively. Finally, it significantly reduces human involvement, as 92.54% of data are automatically annotated in case of disturbing content while no human intervention is required for the NSFW task.
翻译:在线用户生成的内容数量庞大,使得内容调适技术变得至关重要,以保护数字平台受众免受可能导致焦虑、担忧或关切的内容影响。尽管努力开发自动化解决方案以解决该问题,但创建准确模型仍然具有挑战性,因为缺乏适当的具体任务培训数据。人工说明这类数据是一个要求很高的程序,可能严重影响通知员的情感福祉,这与后一种限制直接相关。在本文件中,我们提议采用内容调适框架,利用大型多媒体数据集自动扩展初始培训数据集,以硬示例改进内容调适模式,同时大幅降低人类告示员的参与程度。我们采用的方法是针对数据收集过程中所观察到的不同挑战设计的两种模式适应战略,即缺乏(一) 特定任务的负面数据,或(二) 正面和负面数据。此外,我们引入了适用于数据收集过程的多样性标准,以进一步提高改进后的模型的通用性业绩。对“工作不安全”(NSFW)的初始培训数据集(NSF)进行自动扩展,同时大幅削减了内容调控者的参与程度。