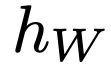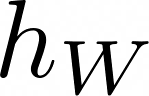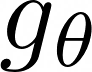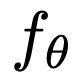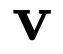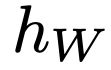Recent advances in deep learning have relied on large, labelled datasets to train high-capacity models. However, collecting large datasets in a time- and cost-efficient manner often results in label noise. We present a method for learning from noisy labels that leverages similarities between training examples in feature space, encouraging the prediction of each example to be similar to its nearest neighbours. Compared to training algorithms that use multiple models or distinct stages, our approach takes the form of a simple, additional regularization term. It can be interpreted as an inductive version of the classical, transductive label propagation algorithm. We thoroughly evaluate our method on datasets evaluating both synthetic (CIFAR-10, CIFAR-100) and realistic (mini-WebVision, Clothing1M, mini-ImageNet-Red) noise, and achieve competitive or state-of-the-art accuracies across all of them.
翻译:最近深层学习的进展依靠大型的标签数据集来培训高容量模型。然而,以时间和成本效率高的方式收集大型数据集往往会导致标签噪音。我们提出的一种方法是从吵闹的标签中学习,利用地物空间培训实例之间的相似之处,鼓励预测每个实例与最近的邻居相似。与使用多种模型或不同阶段的培训算法相比,我们的方法采取的形式是简单、额外的正规化术语。它可以被解释为古典、转基因标签传播算法的感化版本。我们彻底评估了我们评估合成(CIFAR-10、CIFAR-100)和现实(Mini-Web Vision、Strag11M、Mini-ImageNet-Red)噪音的数据集方法,并实现所有这些声音的竞争性或最先进的理解性。