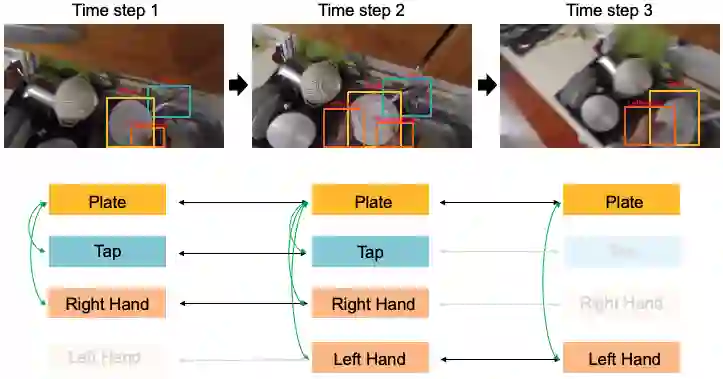
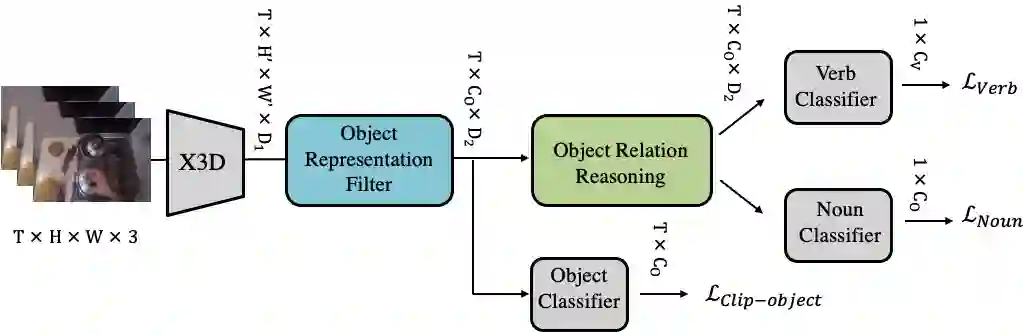
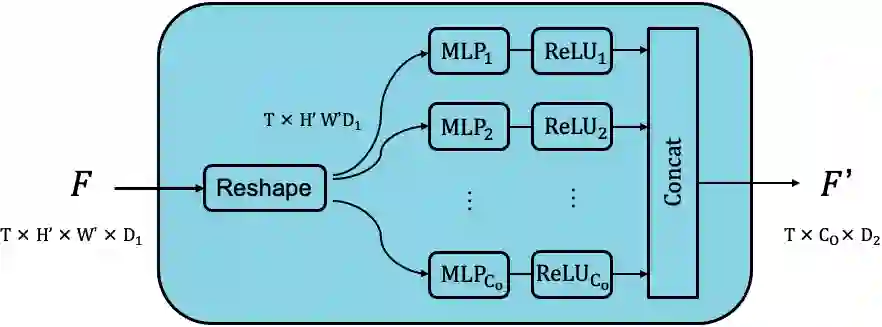
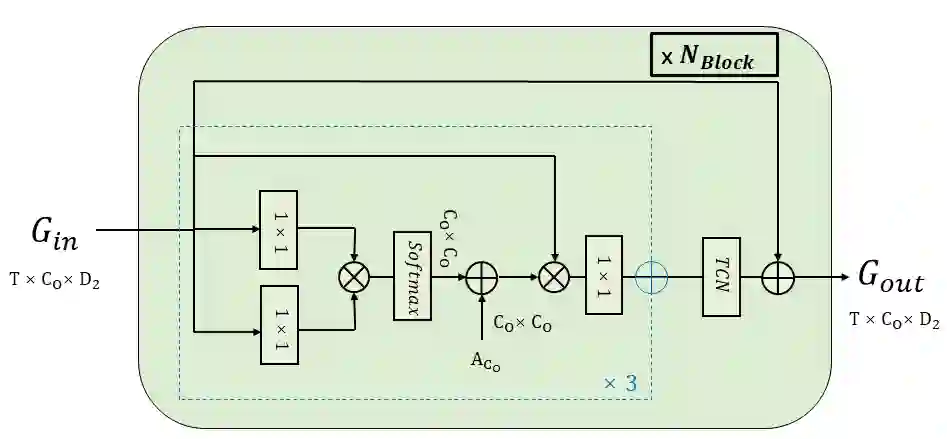
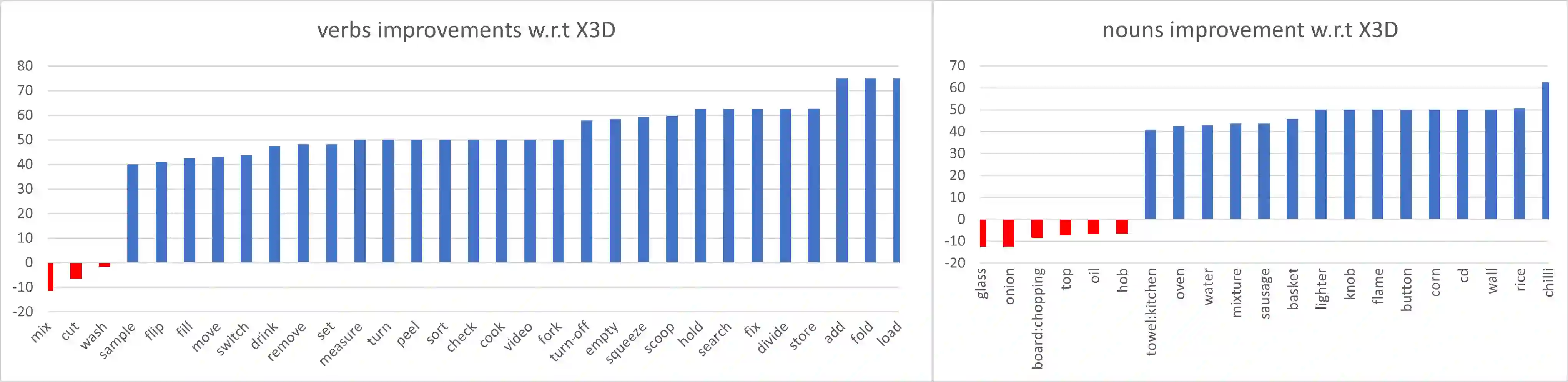
Most action recognition models treat human activities as unitary events. However, human activities often follow a certain hierarchy. In fact, many human activities are compositional. Also, these actions are mostly human-object interactions. In this paper we propose to recognize human action by leveraging the set of interactions that define an action. In this work, we present an end-to-end network: THORN, that can leverage important human-object and object-object interactions to predict actions. This model is built on top of a 3D backbone network. The key components of our model are: 1) An object representation filter for modeling object. 2) An object relation reasoning module to capture object relations. 3) A classification layer to predict the action labels. To show the robustness of THORN, we evaluate it on EPIC-Kitchen55 and EGTEA Gaze+, two of the largest and most challenging first-person and human-object interaction datasets. THORN achieves state-of-the-art performance on both datasets.
翻译:多数行动识别模型将人类活动视为单一事件。然而,人类活动往往遵循某种等级。事实上,许多人类活动是构成性的。此外,这些行动大多是人类与物体的相互作用。在本文件中,我们提议通过利用一系列相互作用来确认人类行动,从而界定一种行动。在这项工作中,我们提出了一个端到端网络:THORN,它可以利用重要的人类-物体和物体的相互作用来预测行动。这个模型建在3D主干网之上。我们模型的关键组成部分是:(1) 模型对象的物体代表过滤器。(2) 捕获物体关系的物体关联推理模块。(3) 用于预测动作标签的分类层。为了显示THORN的稳健性,我们对EPIC-Kitchen55和EGTEGTEA Gaze+进行评估,这是两个最大的和最具挑战性的第一人和人-对象互动数据集中的两个。HORN在两个数据集上都取得了最先进的性能。