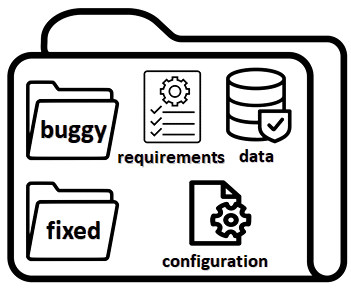
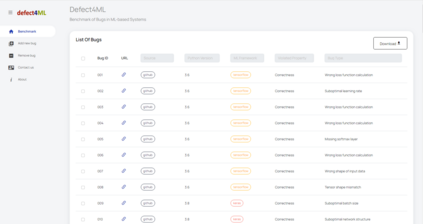
The rapid escalation of applying Machine Learning (ML) in various domains has led to paying more attention to the quality of ML components. There is then a growth of techniques and tools aiming at improving the quality of ML components and integrating them into the ML-based system safely. Although most of these tools use bugs' lifecycle, there is no standard benchmark of bugs to assess their performance, compare them and discuss their advantages and weaknesses. In this study, we firstly investigate the reproducibility and verifiability of the bugs in ML-based systems and show the most important factors in each one. Then, we explore the challenges of generating a benchmark of bugs in ML-based software systems and provide a bug benchmark namely defect4ML that satisfies all criteria of standard benchmark, i.e. relevance, reproducibility, fairness, verifiability, and usability. This faultload benchmark contains 113 bugs reported by ML developers on GitHub and Stack Overflow, using two of the most popular ML frameworks: TensorFlow and Keras. defect4ML also addresses important challenges in Software Reliability Engineering of ML-based software systems, like: 1) fast changes in frameworks, by providing various bugs for different versions of frameworks, 2) code portability, by delivering similar bugs in different ML frameworks, 3) bug reproducibility, by providing fully reproducible bugs with complete information about required dependencies and data, and 4) lack of detailed information on bugs, by presenting links to the bugs' origins. defect4ML can be of interest to ML-based systems practitioners and researchers to assess their testing tools and techniques.
翻译:在不同领域应用机器学习(ML)的快速升级导致对ML组件质量的更多关注。 然后,技术和工具的增加,目的是提高ML组件的质量,安全地将其纳入基于ML的系统。虽然这些工具大多使用错误的生命周期,但没有关于错误的标准基准来评估其性能、比较和讨论其优缺点。在本研究中,我们首先调查ML系统错误的可复制性和可核实性,并显示每个系统中最重要的因素。然后,我们探索在ML软件系统中建立错误基准的挑战,并提供一个错误基准,即缺陷4ML组件的质量,安全地将其纳入基于ML的系统。虽然这些工具大多使用错误的生命周期周期,但没有标准基准来评估错误的周期性,比较它们的工作质量,比较它们之间的缺陷,我们首先调查ML系统中的错误和错误的可核实性,根据基于ML的模型的系统,通过不同版本的错误性能框架来评估ML的精确性,通过快速的版本来评估ML的错误性能,通过不同的软件测试框架来评估关于ML的错误性缺陷和错误性框架。