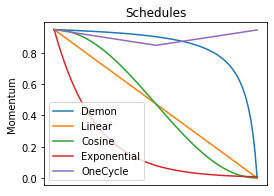
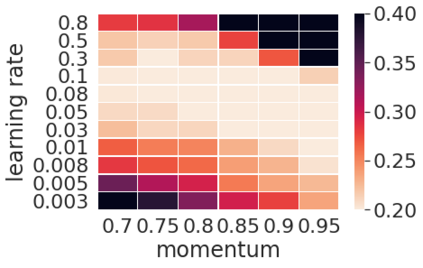
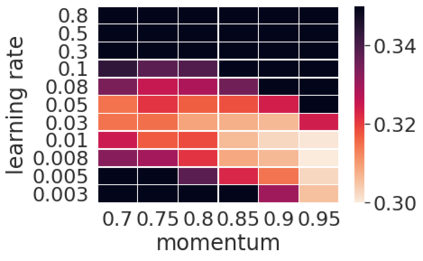
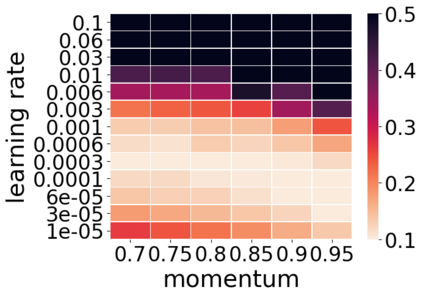
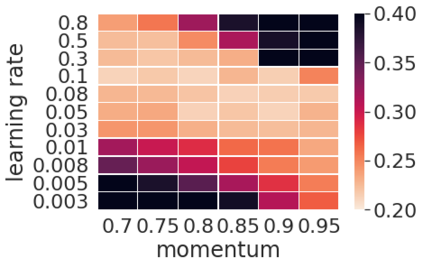
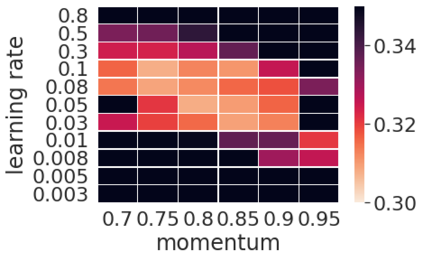
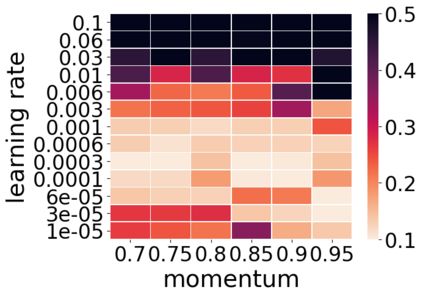
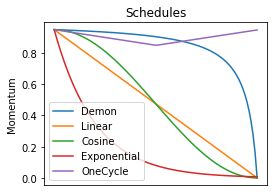
Momentum is a widely used technique for gradient-based optimizers in deep learning. In this paper, we propose a decaying momentum (\textsc{Demon}) rule. We conduct the first large-scale empirical analysis of momentum decay methods for modern neural network optimization, in addition to the most popular learning rate decay schedules. Across 28 relevant combinations of models, epochs, datasets, and optimizers, \textsc{Demon} achieves the highest number of Top-1 and Top-3 finishes at 39\% and 85\% respectively, almost doubling the second-placed learning rate cosine schedule at 17\% and 60\%, respectively. \textsc{Demon} also outperforms other widely used schedulers including, but not limited to, the learning rate step schedule, linear schedule, OneCycle schedule, and exponential schedule. Compared with the widely used learning rate step schedule, \textsc{Demon} is observed to be less sensitive to parameter tuning, which is critical to training neural networks in practice. Results are demonstrated across a variety of settings and architectures, including image classification, generative models, and language models. \textsc{Demon} is easy to implement, requires no additional tuning, and incurs almost no extra computational overhead compared to the vanilla counterparts. Code is readily available.
翻译:momentum 是用于深层学习的基于梯度优化器的一种广泛使用的技术 。 在本文中, 我们提议了一种衰减的势头( textsc{ 守护程序} ) 规则 。 除了最受欢迎的学习速率衰减时间表之外, 我们还对现代神经网络优化的动力衰减方法进行第一次大规模的经验性分析 。 在28种相关的模型、 时代、 数据集和优化组合中,\ textsc{ 守护程序 分别达到39 ⁇ 和 85 ⁇ 的顶级-1 和顶级-3 最高完成率, 几乎将第二位学习速的连线时间表分别翻一番 17 ⁇ 和 60 ⁇ { { { 。\ textsc{ 守护程序} 也优于其他广泛使用的进度表方法, 包括但不限于学习速率步骤表、 线性时间表、 OneCycle 时间表和指数性时间表。 与广泛使用的学习速率步骤时间表相比, 发现对参数调整不太敏感, 这对实践中培训神经网络至关重要 。 显示的结果来自各种设置和模型, 比较易变式的模型和结构,, 需要额外的模型化模型, 进行额外的分析。