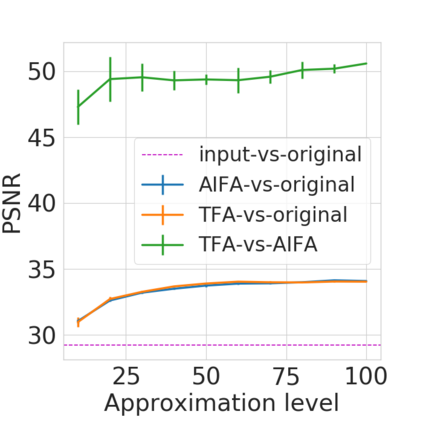
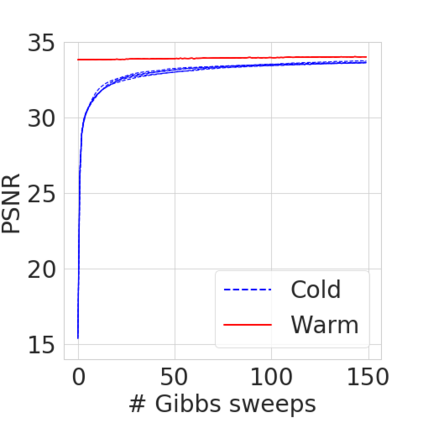
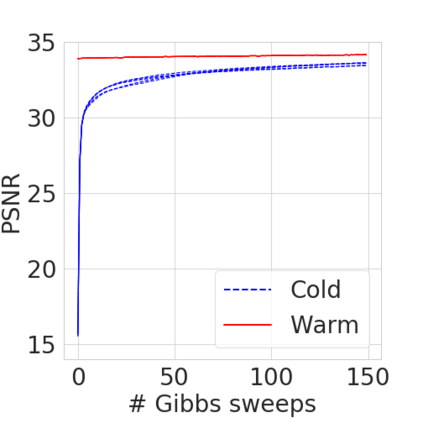
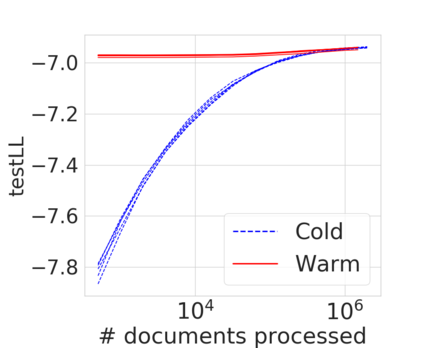
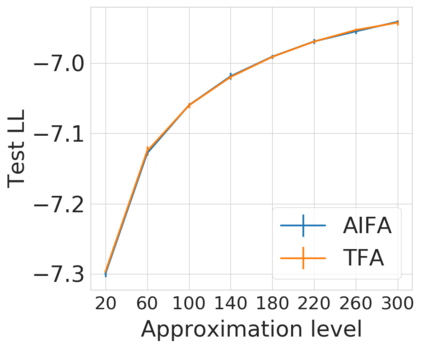
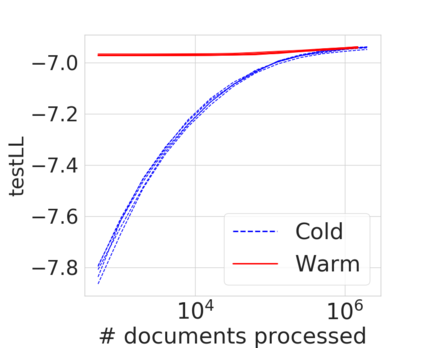
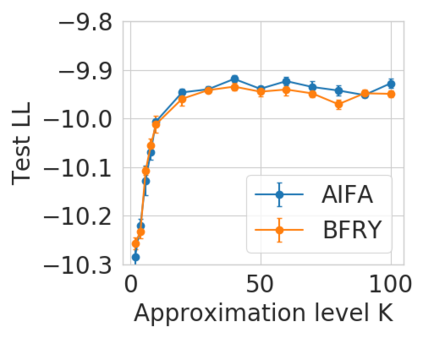
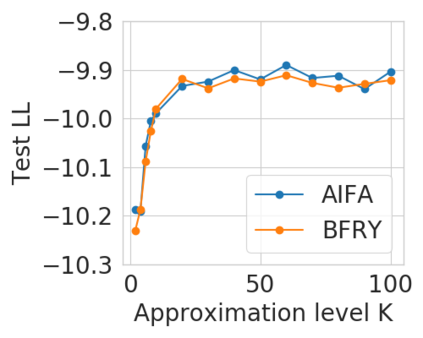
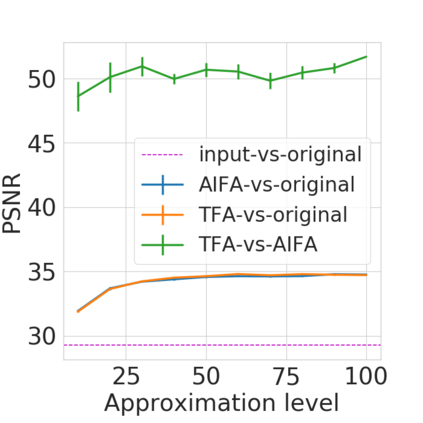
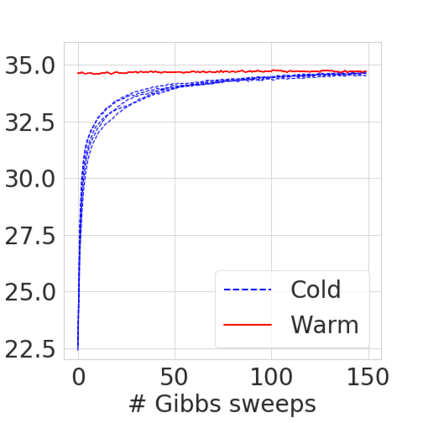
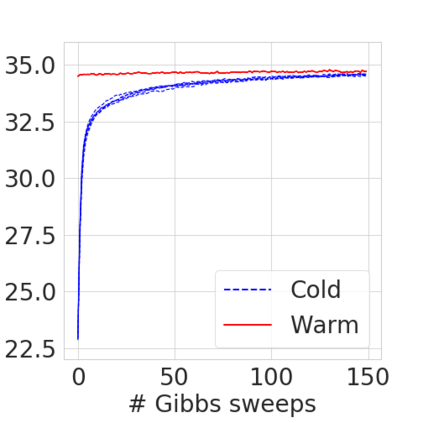
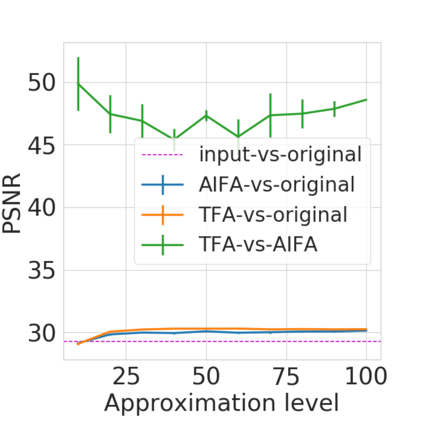
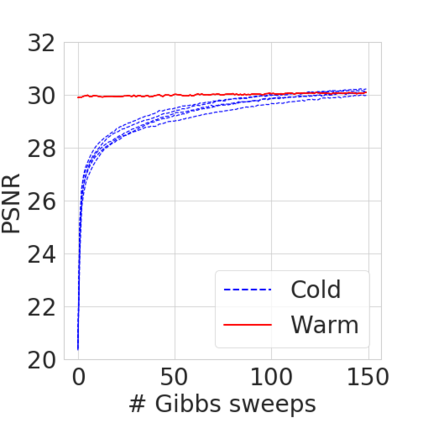
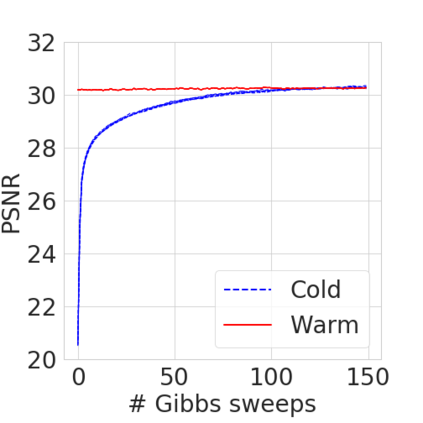
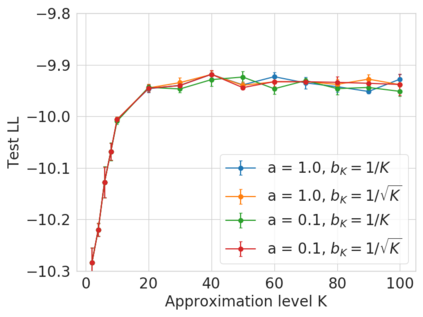
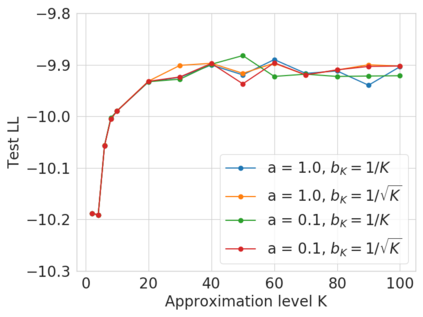
Bayesian nonparametric priors based on completely random measures (CRMs) offer a flexible modeling approach when the number of latent components in a dataset is unknown. However, managing the infinite dimensionality of CRMs typically requires practitioners to derive ad-hoc algorithms, preventing the use of general-purpose inference methods and often leading to long compute times. We propose a general but explicit recipe to construct a simple finite-dimensional approximation that can replace the infinite-dimensional CRMs. Our independent finite approximation (IFA) is a generalization of important cases that are used in practice. The independence of atom weights in our approximation (i) makes the construction well-suited for parallel and distributed computation and (ii) facilitates more convenient inference schemes. We quantify the approximation error between IFAs and the target nonparametric prior. We compare IFAs with an alternative approximation scheme -- truncated finite approximations (TFAs), where the atom weights are constructed sequentially. We prove that, for worst-case choices of observation likelihoods, TFAs are a more efficient approximation than IFAs. However, in real-data experiments with image denoising and topic modeling, we find that IFAs perform very similarly to TFAs in terms of task-specific accuracy metrics.
翻译:基于完全随机的计量方法(CRMS)的巴耶斯非参数前端提供了一种灵活的模型方法,当数据集中潜在组成部分的数量未知时,它就是一种灵活的模型方法。然而,管理CRM的无限维度通常要求从业者得出特别的算法,防止使用通用推论方法,并往往导致长时间的计算时间。我们提出了一个一般但明确的配方,以构建一个简单的有限维近比,可以取代无限的CRMs。我们的独立有限近似(IFA)是实践中使用的重要案例的概括化。我们近似(i)的原子重量独立性使构建适合于平行和分布的计算,以及(ii)更方便的推断计划。我们量化了IFAs与先前目标非参数之间的近似差。我们把IFAs与其他近似近似近似方法 -- -- 短效的有限近似近似值(TFAs) -- -- 即原子重量是按顺序构建的。我们证明,对于最差的观察可能性而言,TFAs(IFA)是比IFA的模型更有效率的模型。但是,在实际任务实验中,我们发现IFAS的精确度实验中以非常的模型为甚。