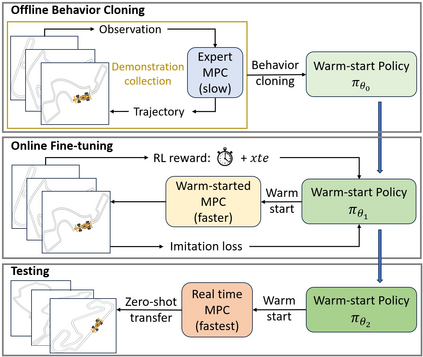
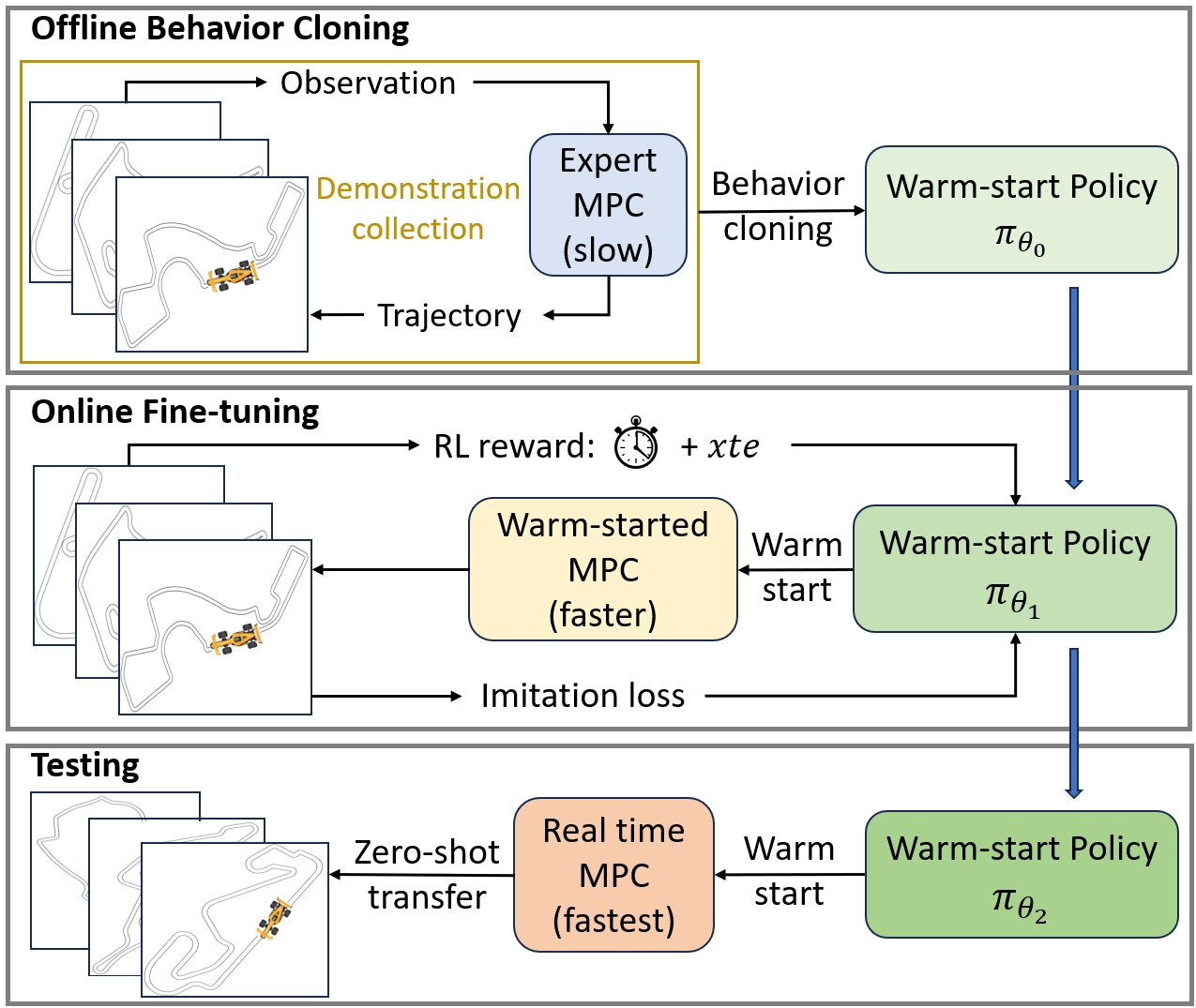
Model Predictive Control (MPC) is widely used in robot control by optimizing a sequence of control outputs over a finite-horizon. Computational approaches for MPC include deterministic methods (e.g., iLQR and COBYLA), as well as sampling-based methods (e.g., MPPI and CEM). However, complex system dynamics and non-convex or non-differentiable cost terms often lead to prohibitive optimization times that limit real-world deployment. Prior efforts to accelerate MPC have limitations on: (i) reusing previous solutions fails under sharp state changes and (ii) pure imitation learning does not target compute efficiency directly and suffers from suboptimality in the training data. To address these, We propose a warm-start framework that learns a policy to generate high-quality initial guesses for MPC solver. The policy is first trained via behavior cloning from expert MPC rollouts and then fine-tuned online with reinforcement learning to directly minimize MPC optimization time. We empirically validate that our approach improves both deterministic and sampling-based MPC methods, achieving up to 21.6% faster optimization and 34.1% more tracking accuracy for deterministic MPC in Formula 1 track path-tracking domain, and improving safety by 100%, path efficiency by 12.8%, and steering smoothness by 7.2% for sampling-based MPC in obstacle-rich navigation domain. These results demonstrate that our framework not only accelerates MPC but also improves overall control performance. Furthermore, it can be applied to a broader range of control algorithms that benefit from good initial guesses.
翻译:暂无翻译