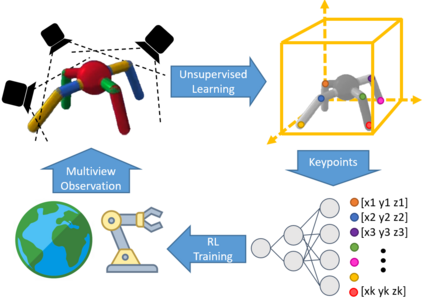
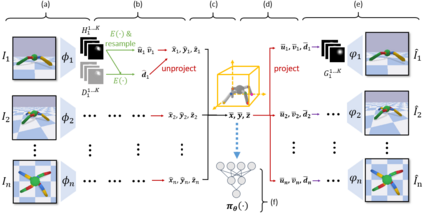
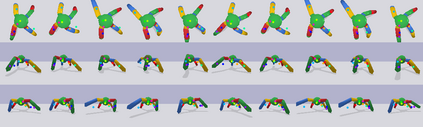
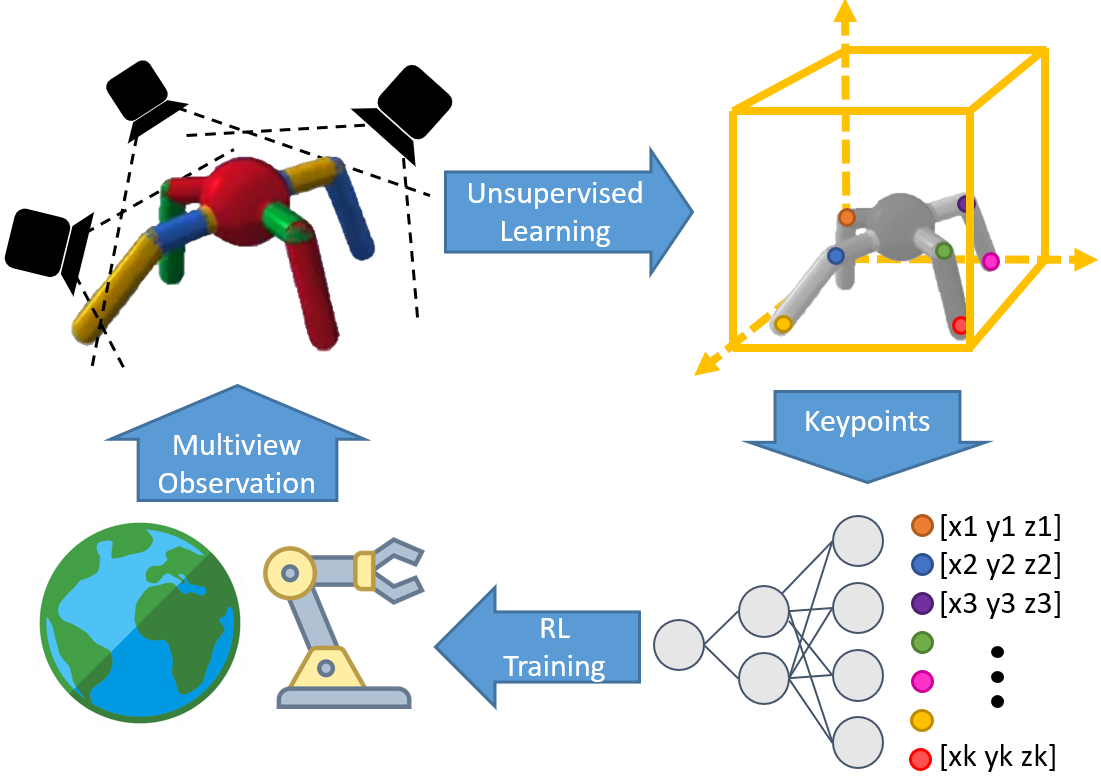
Learning sensorimotor control policies from high-dimensional images crucially relies on the quality of the underlying visual representations. Prior works show that structured latent space such as visual keypoints often outperforms unstructured representations for robotic control. However, most of these representations, whether structured or unstructured are learned in a 2D space even though the control tasks are usually performed in a 3D environment. In this work, we propose a framework to learn such a 3D geometric structure directly from images in an end-to-end unsupervised manner. The input images are embedded into latent 3D keypoints via a differentiable encoder which is trained to optimize both a multi-view consistency loss and downstream task objective. These discovered 3D keypoints tend to meaningfully capture robot joints as well as object movements in a consistent manner across both time and 3D space. The proposed approach outperforms prior state-of-art methods across a variety of reinforcement learning benchmarks. Code and videos at https://buoyancy99.github.io/unsup-3d-keypoints/
翻译:从高维图像中学习感官控制政策,关键取决于基本视觉显示的质量。先前的工程显示,结构化的隐性空间,如视觉关键点,往往优于机器人控制方面结构化的表达方式。然而,大多数这些代表形式,无论结构化还是非结构化,都是在2D空间中学习的,即使控制任务通常是在3D环境中执行的。在这项工作中,我们提议了一个框架,直接从图像中学习3D几何结构,以最终到最终不受监督的方式从图像中学习。输入图像通过不同的编码器嵌入3D潜在关键点,该编码器经过培训,既能优化多视图一致性损失,又能优化下游任务目标。这些发现3D关键点往往能够以一致的方式在时间和3D空间中有意义地捕捉机器人的组合和物体移动。拟议方法超越了各种强化学习基准的先前状态方法。在 https://buoyancy99.github.io/unsup-3d-keys/ 上,代码和视频。