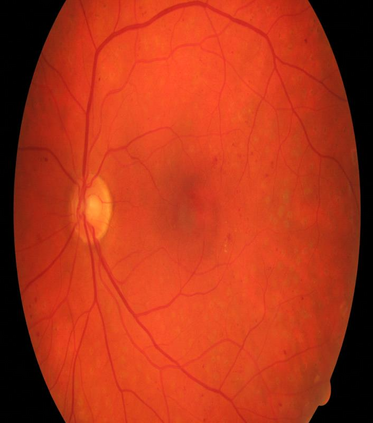
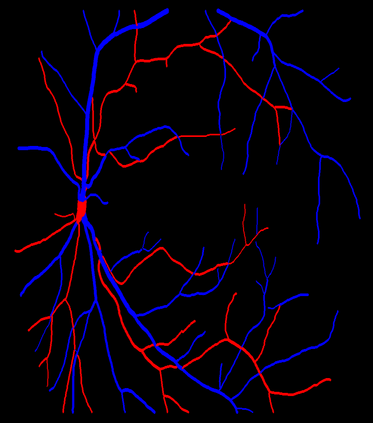
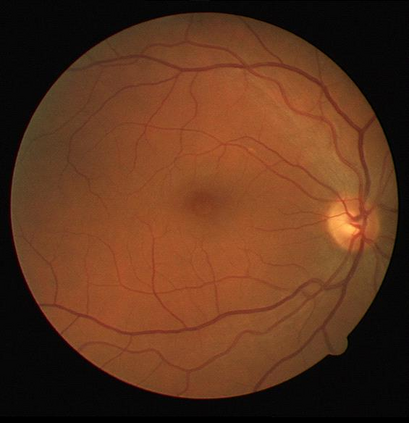
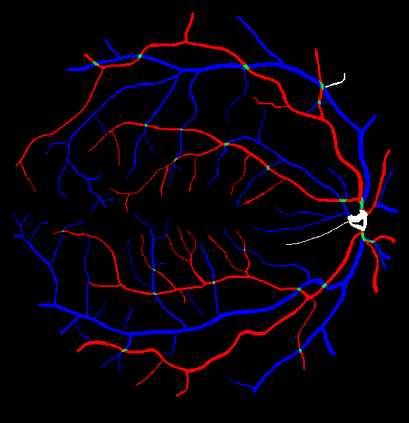
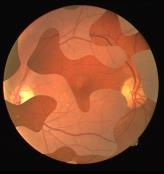
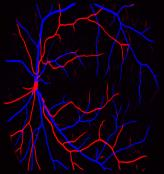
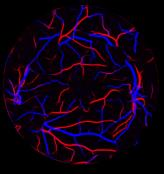
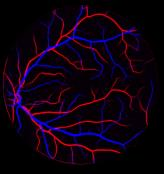
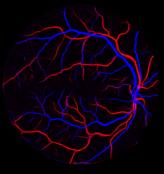
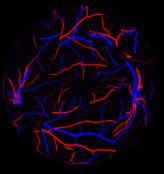
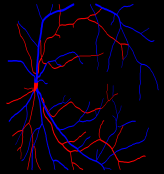
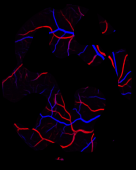
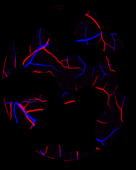
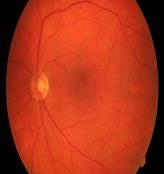
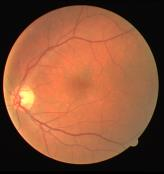
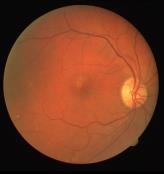
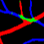
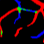
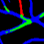
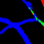
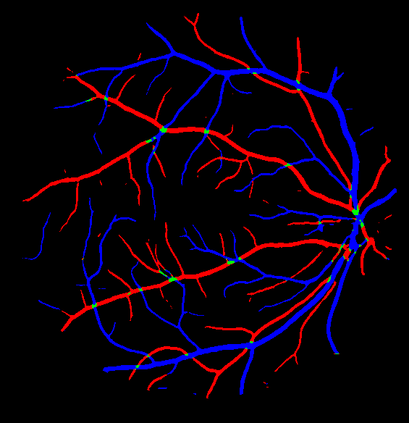
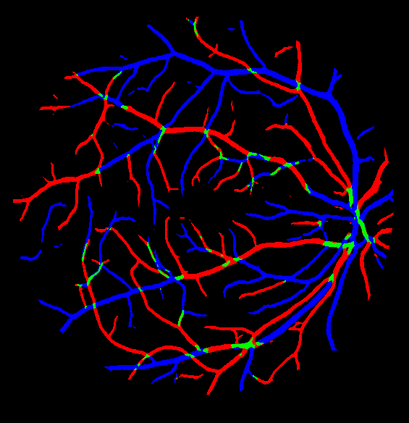
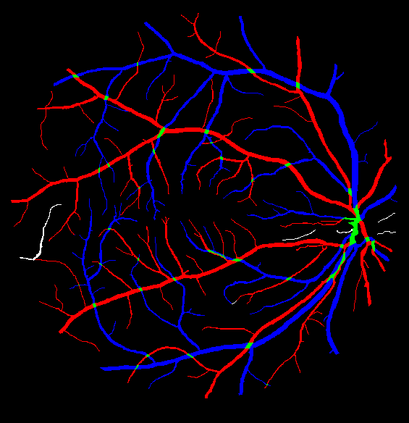
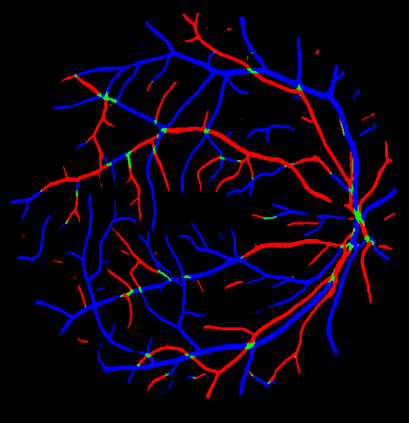
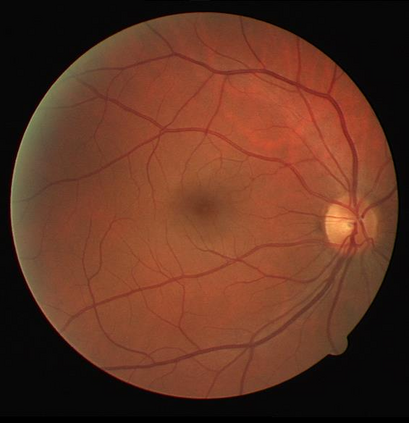
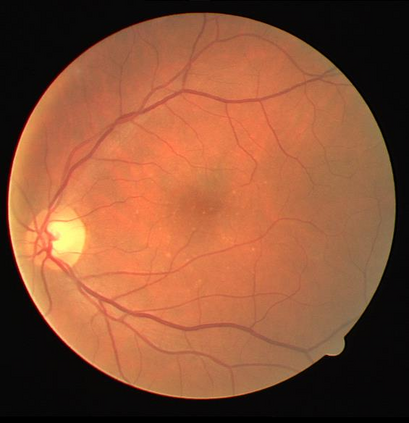
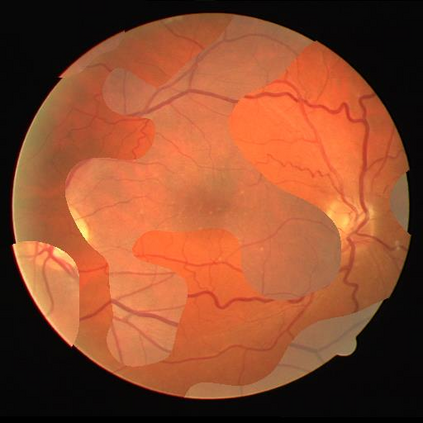
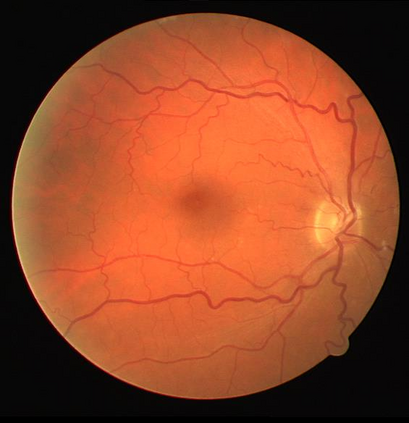
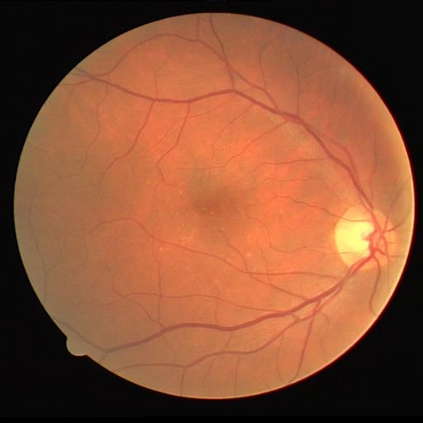
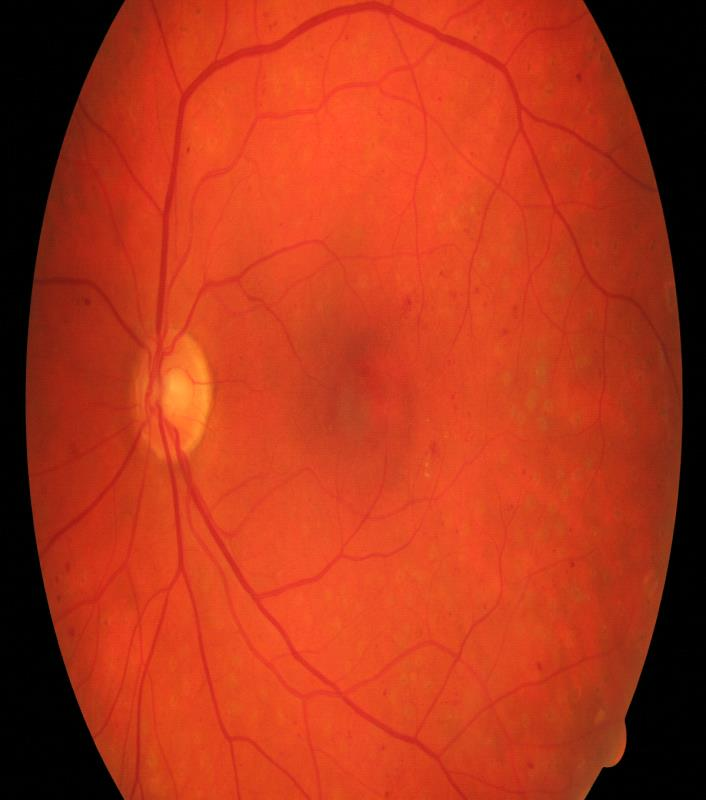
Retinal artery/vein (A/V) classification is a critical technique for diagnosing diabetes and cardiovascular diseases. Although deep learning based methods achieve impressive results in A/V classification, their performances usually degrade severely when being directly applied to another database, due to the domain shift, e.g., caused by the variations in imaging protocols. In this paper, we propose a novel vessel-mixing based consistency regularization framework, for cross-domain learning in retinal A/V classification. Specially, to alleviate the severe bias to source domain, based on the label smooth prior, the model is regularized to give consistent predictions for unlabeled target-domain inputs that are under perturbation. This consistency regularization implicitly introduces a mechanism where the model and the perturbation is opponent to each other, where the model is pushed to be robust enough to cope with the perturbation. Thus, we investigate a more difficult opponent to further inspire the robustness of model, in the scenario of retinal A/V, called vessel-mixing perturbation. Specially, it effectively disturbs the fundus images especially the vessel structures by mixing two images regionally. We conduct extensive experiments on cross-domain A/V classification using four public datasets, which are collected by diverse institutions and imaging devices. The results demonstrate that our method achieves the state-of-the-art cross-domain performance, which is also close to the upper bound obtained by fully supervised learning on target domain.
翻译:视网膜动脉/视网膜(A/V)分类是诊断糖尿病和心血管疾病的关键技术。虽然深深学习方法在A/V分类中取得了令人印象深刻的结果,但由于域变,例如成像协议的变化导致域变换,在直接应用到另一个数据库时,其性能通常会严重退化。在本文件中,我们提议了一个基于船只混合的新的一致性规范框架,用于在视网膜A/V分类中进行交叉学习。特别为了减轻对源域的严重偏差,在先前标签平稳的基础上,该模型被常规化,以便对处于扰动状态的无标签目标持续投入作出一致的预测。由于域变换,例如成成像程序的变化,其性能通常会在另一个数据库中出现一种机制,使模型和扰动相互对立,使模型的强度足以应对扰动。因此,我们调查一个更困难的对手,以进一步激励模型的稳健性,在 retinal A/V假设中,称为船舶混合扰动。特别,它实际上扰乱了对未标域目标持续输入的域域域域内输入目标输入的输入的输入,特别是我们所收集的图象的图象结构,通过区域图象结构,我们通过收集的图象学的图象结构,从而在进行广泛的图象学上进行广泛的交叉的图象学上,我们用四个式的图解的图。我们用四个的图的图的图的图。我们所收集的图的图的图的图的图的图。