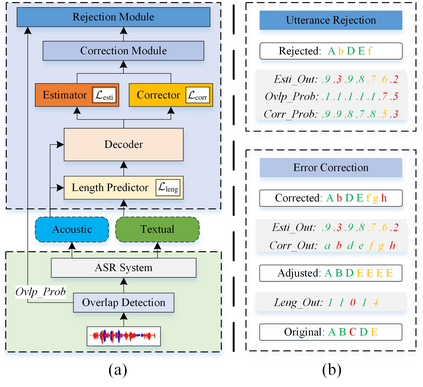
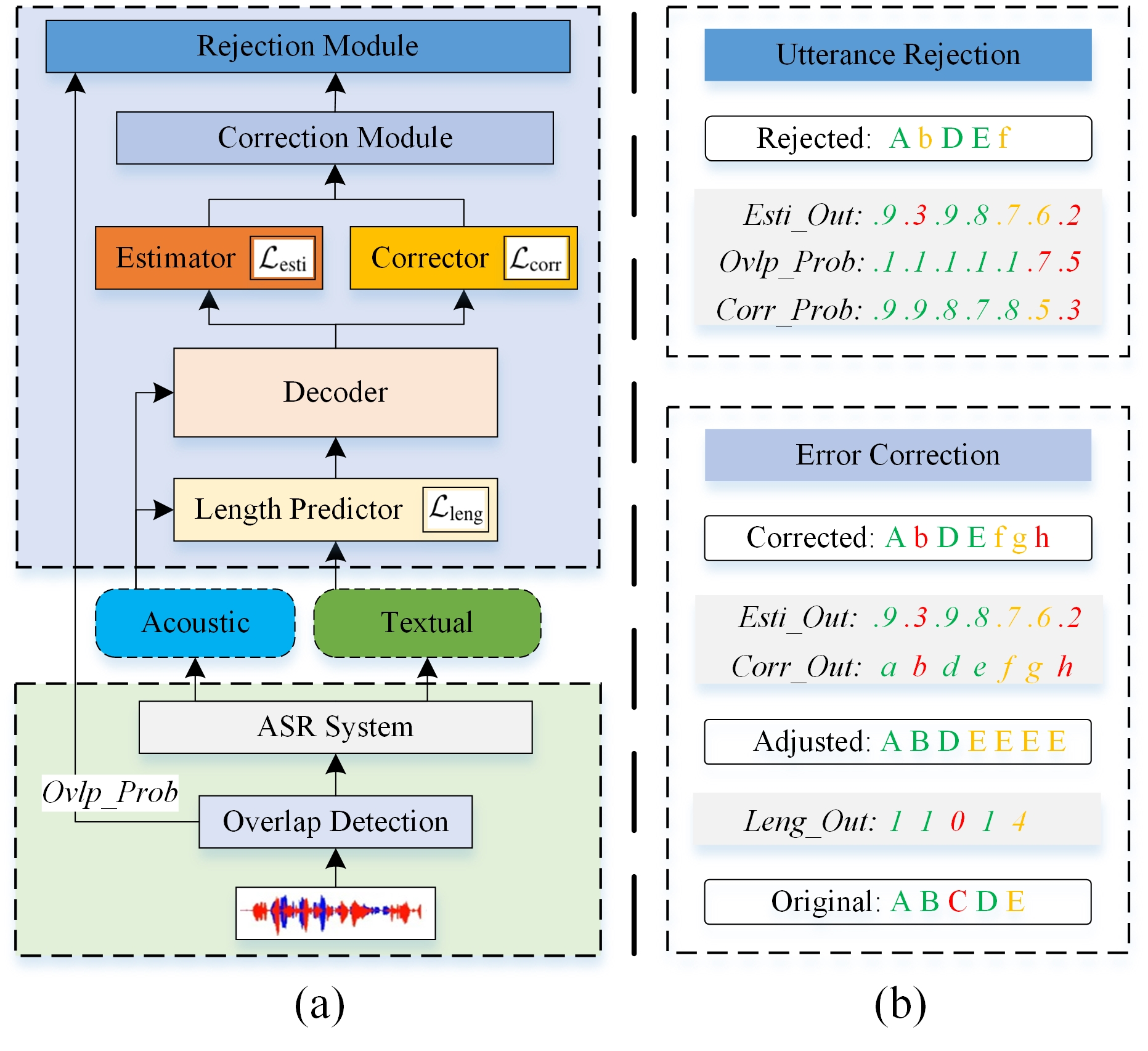
Although modern automatic speech recognition (ASR) systems can achieve high performance, they may produce errors that weaken readers' experience and do harm to downstream tasks. To improve the accuracy and reliability of ASR hypotheses, we propose a cross-modal post-processing system for speech recognizers, which 1) fuses acoustic features and textual features from different modalities, 2) joints a confidence estimator and an error corrector in multi-task learning fashion and 3) unifies error correction and utterance rejection modules. Compared with single-modal or single-task models, our proposed system is proved to be more effective and efficient. Experiment result shows that our post-processing system leads to more than 10% relative reduction of character error rate (CER) for both single-speaker and multi-speaker speech on our industrial ASR system, with about 1.7ms latency for each token, which ensures that extra latency introduced by post-processing is acceptable in streaming speech recognition.
翻译:虽然现代自动语音识别系统可以取得高性能,但可能会产生错误,削弱读者的经验,损害下游任务。为了提高ASR假设的准确性和可靠性,我们提议为语音识别者建立一个跨模式后处理系统,该系统:(1) 结合不同模式的声学特征和文字特征,(2) 在多任务学习时将信任估计器和错误纠正器连接在一起,(3) 统一错误纠正和断语模块。与单一模式或单一任务模式相比,我们提议的系统被证明更有成效和效率更高。实验结果显示,我们的后处理系统导致我们的工业ASR系统单声器和多声器语言的性格错误率降低10%以上,每个符号约1.7米的悬浮度,这确保了后处理引入的超静脉冲识别可以接受。