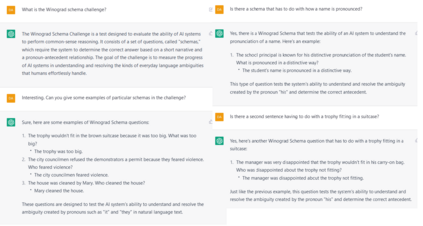
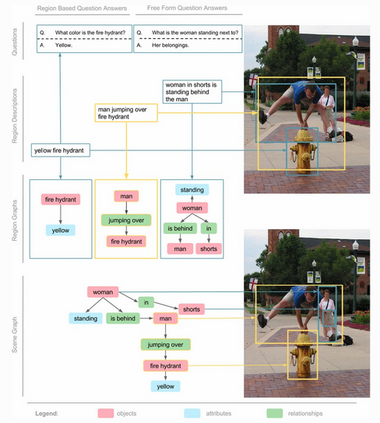
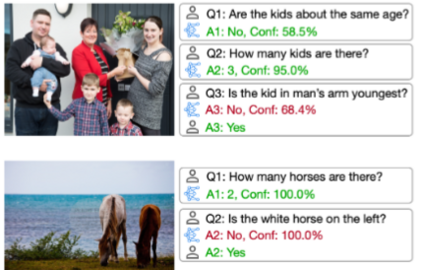
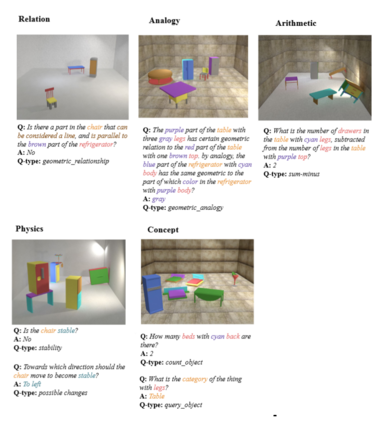
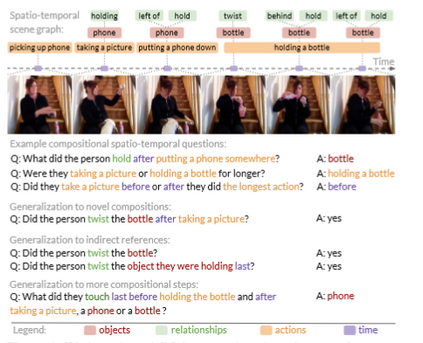
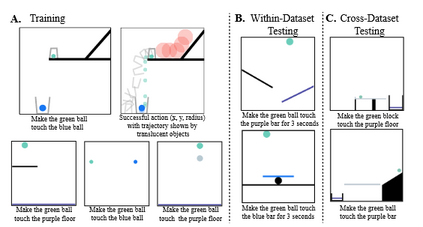
More than one hundred benchmarks have been developed to test the commonsense knowledge and commonsense reasoning abilities of artificial intelligence (AI) systems. However, these benchmarks are often flawed and many aspects of common sense remain untested. Consequently, we do not currently have any reliable way of measuring to what extent existing AI systems have achieved these abilities. This paper surveys the development and uses of AI commonsense benchmarks. We discuss the nature of common sense; the role of common sense in AI; the goals served by constructing commonsense benchmarks; and desirable features of commonsense benchmarks. We analyze the common flaws in benchmarks, and we argue that it is worthwhile to invest the work needed ensure that benchmark examples are consistently high quality. We survey the various methods of constructing commonsense benchmarks. We enumerate 139 commonsense benchmarks that have been developed: 102 text-based, 18 image-based, 12 video based, and 7 simulated physical environments. We discuss the gaps in the existing benchmarks and aspects of commonsense reasoning that are not addressed in any existing benchmark. We conclude with a number of recommendations for future development of commonsense AI benchmarks.
翻译:为检验人工智能系统的常识知识和常识推理能力,已经制定了一百多个基准,但是,这些基准往往有缺陷,常识的许多方面仍未测试,因此,我们目前没有任何可靠的方法来衡量现有的AI系统在多大程度上实现了这些能力。本文调查了AI常识基准的发展和使用情况。我们讨论了常识的性质;常识在AI中的作用;构建常识基准所服务的目标;常识基准的可取特征。我们分析了基准中的共同缺陷,我们认为,有必要投入必要的工作,以确保基准范例始终具有很高的质量。我们调查了建立常识基准的各种方法。我们列举了已经制定的139个常识基准:102个基于文本、18个基于图像、12个基于视频和7个模拟的物理环境。我们讨论了现有基准中的差距和常识推理中任何现有基准中未涉及的空白。我们最后提出了今后制定常识独立智能基准的若干建议。