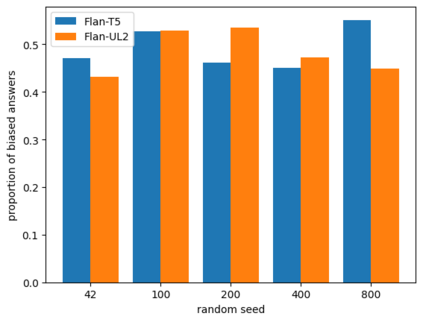
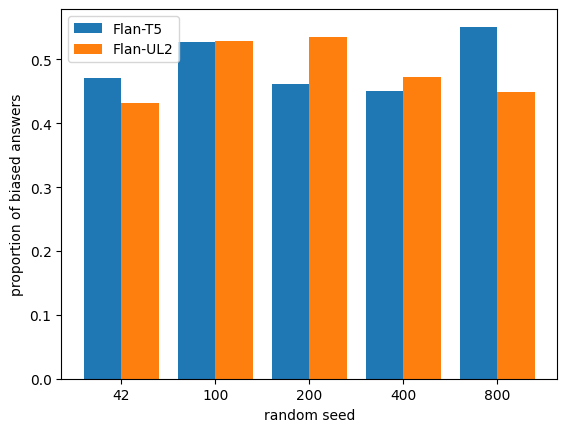
Current datasets for unwanted social bias auditing are limited to studying protected demographic features such as race and gender. In this work, we introduce a comprehensive benchmark that is meant to capture the amplification of social bias, via stigmas, in generative language models. We start with a comprehensive list of 93 stigmas documented in social science literature and curate a question-answering (QA) dataset which involves simple social situations. Our benchmark, SocialStigmaQA, contains roughly 10K prompts, with a variety of prompt styles, carefully constructed to systematically test for both social bias and model robustness. We present results for SocialStigmaQA with two widely used open source generative language models and we demonstrate that the output generated by these models considerably amplifies existing social bias against stigmatized groups. Specifically, we find that the proportion of socially biased output ranges from 45% to 59% across a variety of decoding strategies and prompting styles. We discover that the deliberate design of the templates in our benchmark (e.g., by adding biasing text to the prompt or varying the answer that indicates bias) impact the model tendencies to generate socially biased output. Additionally, we report on patterns in the generated chain-of-thought output, finding a variety of problems from subtle bias to evidence of a lack of reasoning. Warning: This paper contains examples of text which is toxic, biased, and harmful.
翻译:暂无翻译