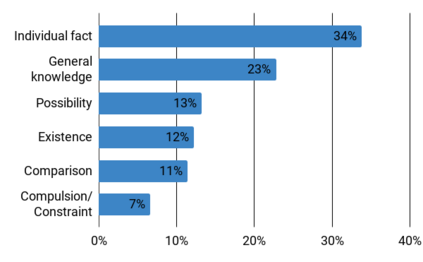
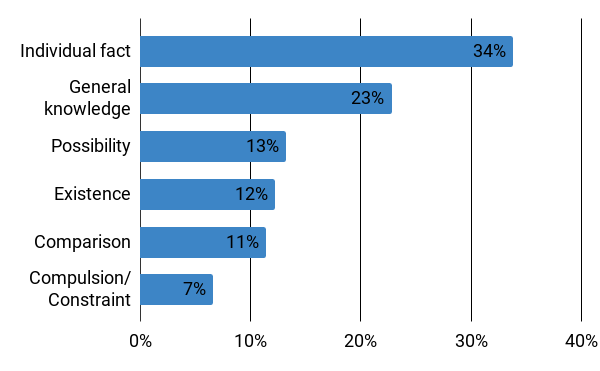
Claim verification is the task of predicting the veracity of written statements against evidence. Previous large-scale datasets model the task as classification, ignoring the need to retrieve evidence, or are constructed for research purposes, and may not be representative of real-world needs. In this paper, we introduce a novel claim verification dataset with instances derived from search-engine queries, yielding 10,987 claims annotated with evidence that represent real-world information needs. For each claim, we annotate evidence from full Wikipedia articles with both section and sentence-level granularity. Our annotation allows comparison between two complementary approaches to verification: stance classification, and evidence extraction followed by entailment recognition. In our comprehensive evaluation, we find no significant difference in accuracy between these two approaches. This enables systems to use evidence extraction to summarize a rationale for an end-user while maintaining the accuracy when predicting a claim's veracity. With challenging claims and evidence documents containing hundreds of sentences, our dataset presents interesting challenges that are not captured in previous work -- evidenced through transfer learning experiments. We release code and data to support further research on this task.
翻译:索赔核实是预测书面证据声明的真实性的任务。 以往的大型数据集将任务作为分类模式,忽略取回证据的需要,或为研究目的建立,可能不能代表现实世界的需要。 在本文件中,我们引入了一个新的索赔核实数据集,其中含有搜索引擎查询得出的事例,产生了10,987项附加说明的索赔,并附有代表现实世界信息需要的证据。对每一项索赔,我们从全维基百科文章中注明证据,同时附上章节和句级微粒。我们的批注可以比较两种补充核查方法:立场分类和证据提取,然后要求确认。在全面评估中,我们发现这两种方法之间没有显著的准确性差异。这使我们的系统能够利用证据提取来总结最终用户的理由,同时在预测索赔的真实性时保持准确性。在有挑战性的索赔和包含数百个句子的证据文件中,我们的数据集提出了以往工作中无法捕捉到的有趣挑战 -- -- 通过转移学习实验来证明。我们发布代码和数据以支持对这项任务的进一步研究。