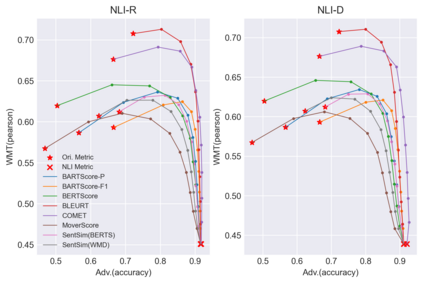
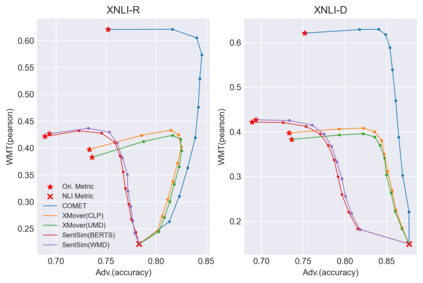
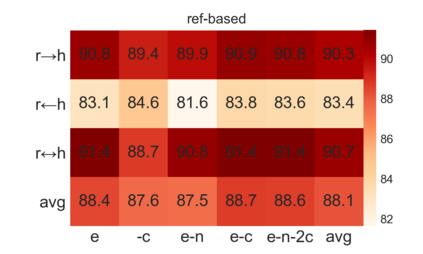
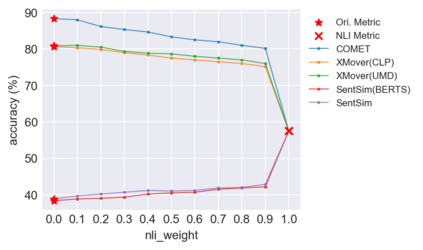
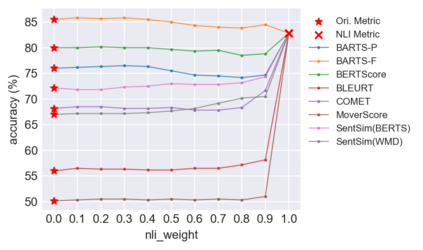
Recently proposed BERT-based evaluation metrics perform well on standard evaluation benchmarks but are vulnerable to adversarial attacks, e.g., relating to factuality errors. We argue that this stems (in part) from the fact that they are models of semantic similarity. In contrast, we develop evaluation metrics based on Natural Language Inference (NLI), which we deem a more appropriate modeling. We design a preference-based adversarial attack framework and show that our NLI based metrics are much more robust to the attacks than the recent BERT-based metrics. On standard benchmarks, our NLI based metrics outperform existing summarization metrics, but perform below SOTA MT metrics. However, when we combine existing metrics with our NLI metrics, we obtain both higher adversarial robustness (+20% to +30%) and higher quality metrics as measured on standard benchmarks (+5% to +25%).
翻译:最近提出的基于BERT的评价指标在标准评价基准方面表现良好,但很容易受到对抗性攻击,例如,与事实质量错误有关的攻击。我们争辩说,这(部分)是由于它们是语义相似的模型。相反,我们根据自然语言推论(NLI)制定了评价指标,我们认为这更适合建模。我们设计了一个基于优惠的对抗攻击框架,并表明我们基于NLI的指标比基于BERT的最近指标对攻击的力度要强得多。在标准基准方面,我们基于NLI的衡量指标优于现有总和化指标,但低于SOTA MTM 指标。然而,当我们将现有指标与我们的NLI指标结合起来时,我们既获得了更高的对抗性强(+20%至+30%),又获得了根据标准基准衡量的更高质量指标(+5%至+25%)。