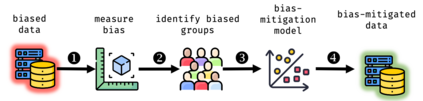
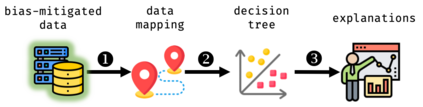
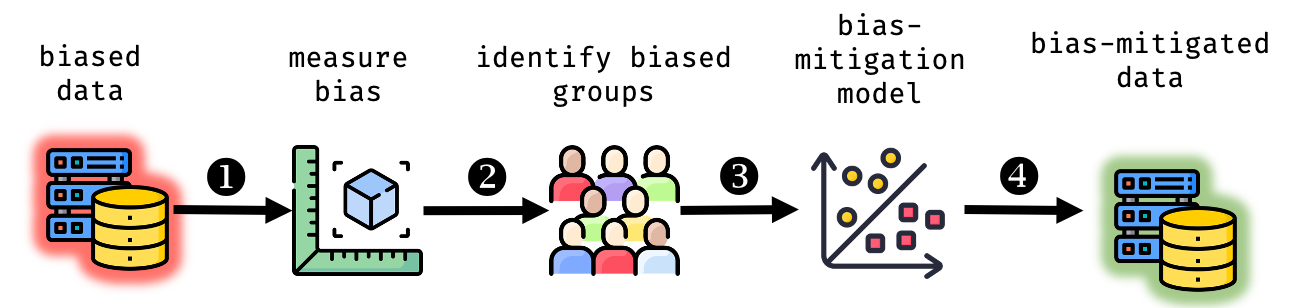
In machine learning systems, bias mitigation approaches aim to make outcomes fairer across privileged and unprivileged groups. Bias mitigation methods work in different ways and have known "waterfall" effects, e.g., mitigating bias at one place may manifest bias elsewhere. In this paper, we aim to characterise impacted cohorts when mitigation interventions are applied. To do so, we treat intervention effects as a classification task and learn an explainable meta-classifier to identify cohorts that have altered outcomes. We examine a range of bias mitigation strategies that work at various stages of the model life cycle. We empirically demonstrate that our meta-classifier is able to uncover impacted cohorts. Further, we show that all tested mitigation strategies negatively impact a non-trivial fraction of cases, i.e., people who receive unfavourable outcomes solely on account of mitigation efforts. This is despite improvement in fairness metrics. We use these results as a basis to argue for more careful audits of static mitigation interventions that go beyond aggregate metrics.
翻译:暂无翻译