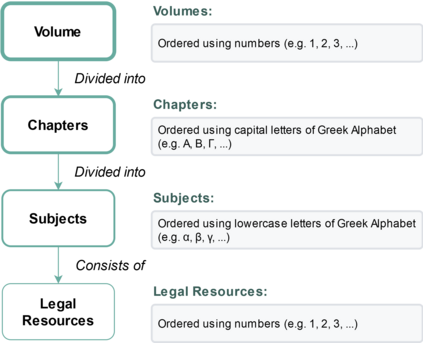
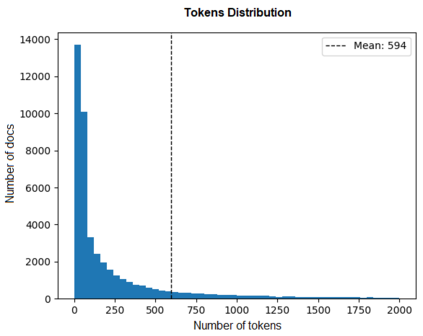
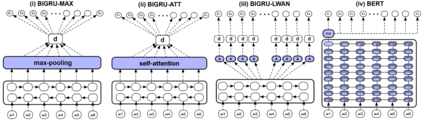
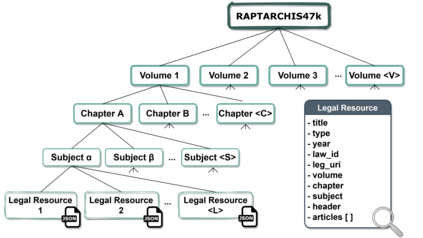
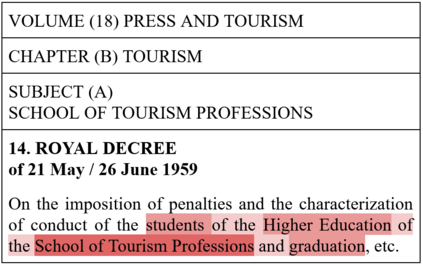
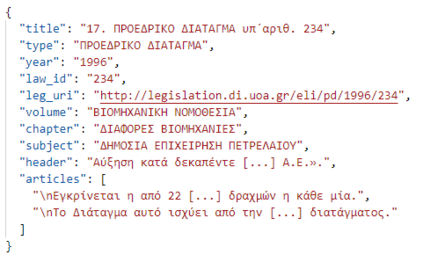
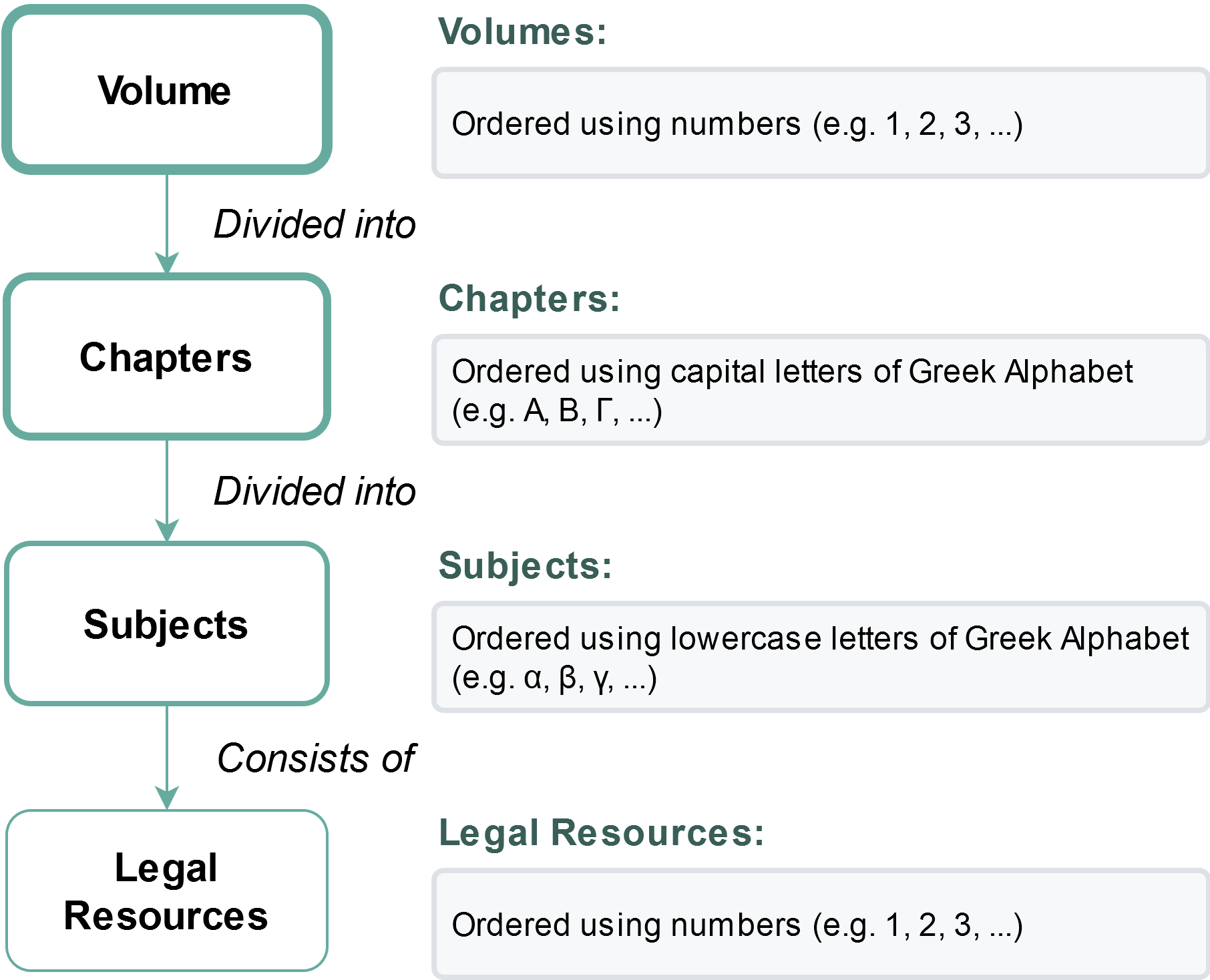
In this work, we study the task of classifying legal texts written in the Greek language. We introduce and make publicly available a novel dataset based on Greek legislation, consisting of more than 47 thousand official, categorized Greek legislation resources. We experiment with this dataset and evaluate a battery of advanced methods and classifiers, ranging from traditional machine learning and RNN-based methods to state-of-the-art Transformer-based methods. We show that recurrent architectures with domain-specific word embeddings offer improved overall performance while being competitive even to transformer-based models. Finally, we show that cutting-edge multilingual and monolingual transformer-based models brawl on the top of the classifiers' ranking, making us question the necessity of training monolingual transfer learning models as a rule of thumb. To the best of our knowledge, this is the first time the task of Greek legal text classification is considered in an open research project, while also Greek is a language with very limited NLP resources in general.
翻译:在这项工作中,我们研究用希腊语对法律文本进行分类的任务。我们根据希腊立法推出并公布一套新数据集,由47,000多官方希腊分类立法资源组成。我们试验这一数据集并评价一组先进的方法和分类方法,从传统的机器学习和基于RNN的方法到基于最新技术的变异器的方法。我们显示,带有特定域名嵌嵌入的经常性结构提供了更好的整体性能,同时甚至具有竞争力,甚至以变异器为基础的模型。最后,我们显示,最先进的多语种和单一语言变异器模型在分类者排名的顶端上是勃起,使我们质疑培训单语言转移学习模型的必要性,以此作为一个大拇指规则。据我们所知,这是首次在一个开放的研究项目中考虑希腊法律文本分类的任务,而希腊语一般也是一种语言,只有非常有限的NLP资源。