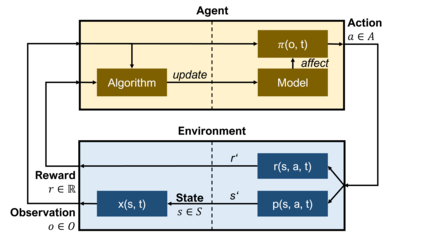
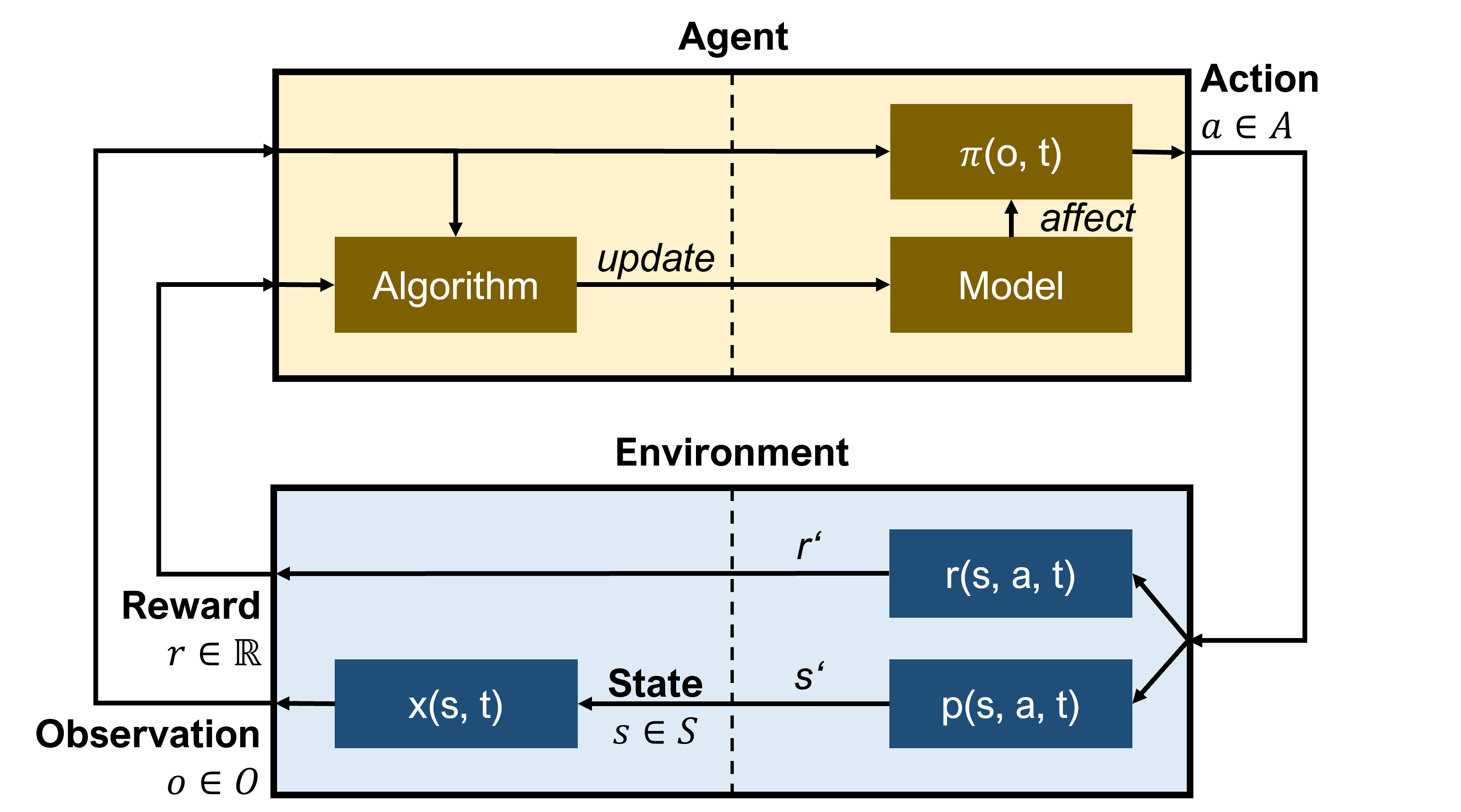
We present an empirical study on the use of continual learning (CL) methods in a reinforcement learning (RL) scenario, which, to the best of our knowledge, has not been described before. CL is a very active recent research topic concerned with machine learning under non-stationary data distributions. Although this naturally applies to RL, the use of dedicated CL methods is still uncommon. This may be due to the fact that CL methods often assume a decomposition of CL problems into disjoint sub-tasks of stationary distribution, that the onset of these sub-tasks is known, and that sub-tasks are non-contradictory. In this study, we perform an empirical comparison of selected CL methods in a RL problem where a physically simulated robot must follow a racetrack by vision. In order to make CL methods applicable, we restrict the RL setting and introduce non-conflicting subtasks of known onset, which are however not disjoint and whose distribution, from the learner's point of view, is still non-stationary. Our results show that dedicated CL methods can significantly improve learning when compared to the baseline technique of "experience replay".
翻译:我们对在强化学习(RL)情景中持续学习(CL)方法的使用进行了实证研究,但据我们所知,这种研究是以前没有描述过的。 CL是一个非常活跃的近期研究课题,涉及非静止数据分布下的机器学习。虽然这自然适用于RL,但专用CL方法的使用仍然不常见。这可能是由于CL方法往往假定CL问题分解成固定分布的分任务,这些子任务的开始是已知的,而子任务是非重叠的。在本研究中,我们对在RL问题中选定的CL方法进行了实证性比较,在RL问题中,一个物理模拟机器人必须按视觉沿赛道学习。为了使CL方法适用CL方法,我们限制RL设置并引入已知发端的非相冲突子任务,而从学习者的观点看,这些子任务的分配仍然是非固定的。我们的结果显示,专门CL方法可以大大改进学习“经验再演练”基线的学习。