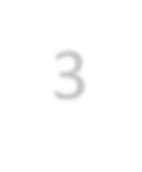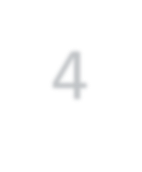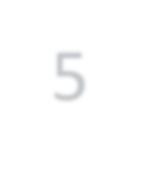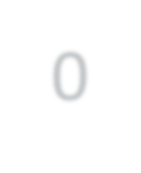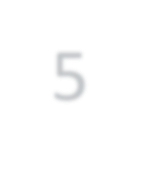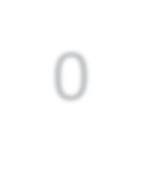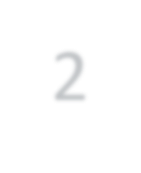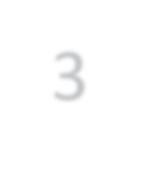Modern approaches for semantic segmentation usually employ dilated convolutions in the backbone to extract high-resolution feature maps, which brings heavy computation complexity and memory footprint. To replace the time and memory consuming dilated convolutions, we propose a novel joint upsampling module named Joint Pyramid Upsampling (JPU) by formulating the task of extracting high-resolution feature maps into a joint upsampling problem. With the proposed JPU, our method reduces the computation complexity by more than three times without performance loss. Experiments show that JPU is superior to other upsampling modules, which can be plugged into many existing approaches to reduce computation complexity and improve performance. By replacing dilated convolutions with the proposed JPU module, our method achieves the state-of-the-art performance in Pascal Context dataset (mIoU of 53.13%) and ADE20K dataset (final score of 0.5584) while running 3 times faster.
翻译:语义分解的现代方法通常在主干线中采用放大变速法来提取高分辨率特征图,这带来沉重的计算复杂度和记忆足迹。为了替换时间和记忆消耗的变速率,我们建议使用一个名为联合金字塔抽样(JPU)的新颖混合抽样模块,将提取高分辨率特征图的任务发展成一个联合抽样问题。在拟议的 JPU 中,我们的方法将计算复杂度减少三倍以上,而不会造成性能损失。实验显示, JPU 优于其他加压模块,可以将其插入到许多现有的方法中,以减少计算复杂度和改善性能。通过用拟议的 JPUM 模块取代变速变速率模块,我们的方法在Pascal 环境数据集(MIOU,53.13%) 和 ADE20K 数据集(最后得分为0.5584) 中达到最新性能,同时速度为3倍。