
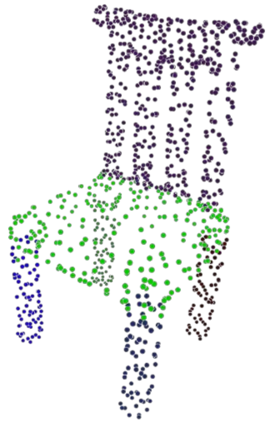
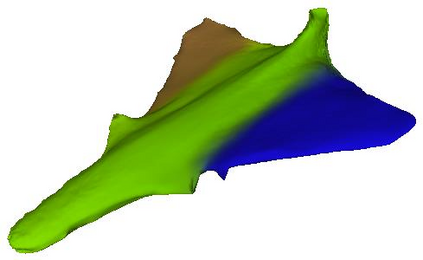
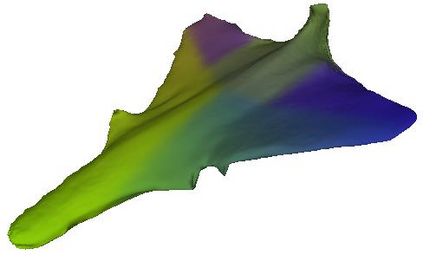
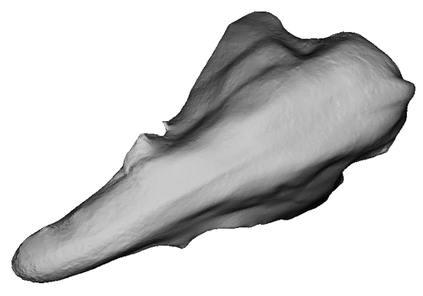
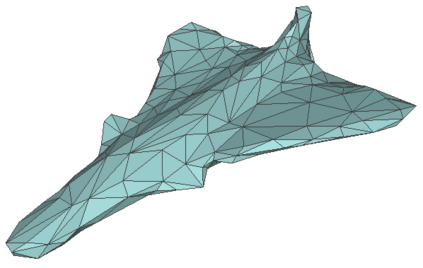
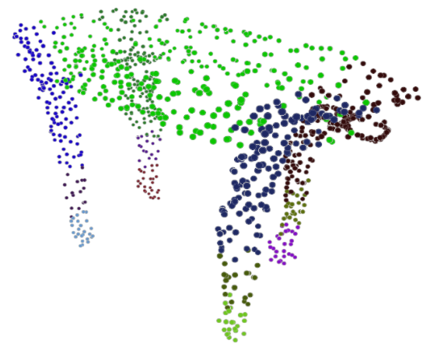
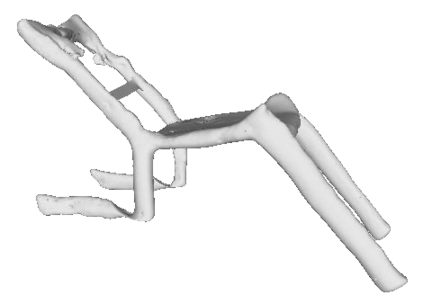
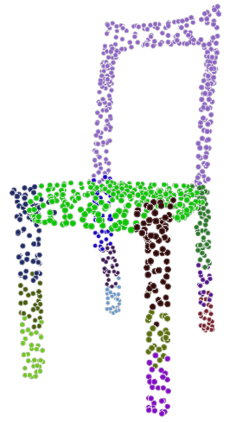
Given a picture of a chair, could we extract the 3-D shape of the chair, animate its plausible articulations and motions, and render in-situ in its original image space? The above question prompts us to devise an automated approach to extract and manipulate articulated objects in single images. Comparing with previous efforts on object manipulation, our work goes beyond 2-D manipulation and focuses on articulable objects, thus introduces greater flexibility for possible object deformations. The pipeline of our approach starts by reconstructing and refining a 3-D mesh representation of the object of interest from an input image; its control joints are predicted by exploiting the semantic part segmentation information; the obtained object 3-D mesh is then rigged \& animated by non-rigid deformation, and rendered to perform in-situ motions in its original image space. Quantitative evaluations are carried out on 3-D reconstruction from single images, an established task that is related to our pipeline, where our results surpass those of the SOTAs by a noticeable margin. Extensive visual results also demonstrate the applicability of our approach.
翻译:根据一张椅子的图片,我们能否提取椅子的三维形状,用输入图像来模拟其貌似合理的表达和动作,并在原始图像空间中进行原样化?上述问题促使我们设计一种自动方法来提取和操作单个图像中的表达器。比照以往关于物体操纵的努力,我们的工作超出了二维操纵,侧重于可动物体,从而为可能的物体变形提供了更大的灵活性。我们的方法的管道开始于从输入图像中重建和改进一个3D网格表示对象的意向;其控制连接是通过利用语义部分分割信息预测的;获得的物体三维网格随后被非硬性变形所驱使,并用于在原始图像空间进行现场运动。从单一图像中进行3D重建的定量评估,这是与我们的管道有关的一项既定任务,我们的成果在显著的边缘超过SOTA。广泛的视觉结果也显示了我们的方法的可适用性。









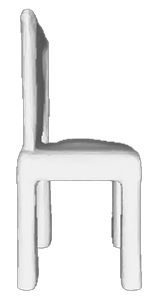























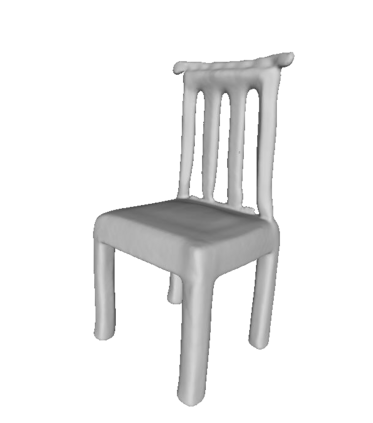






















































相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

