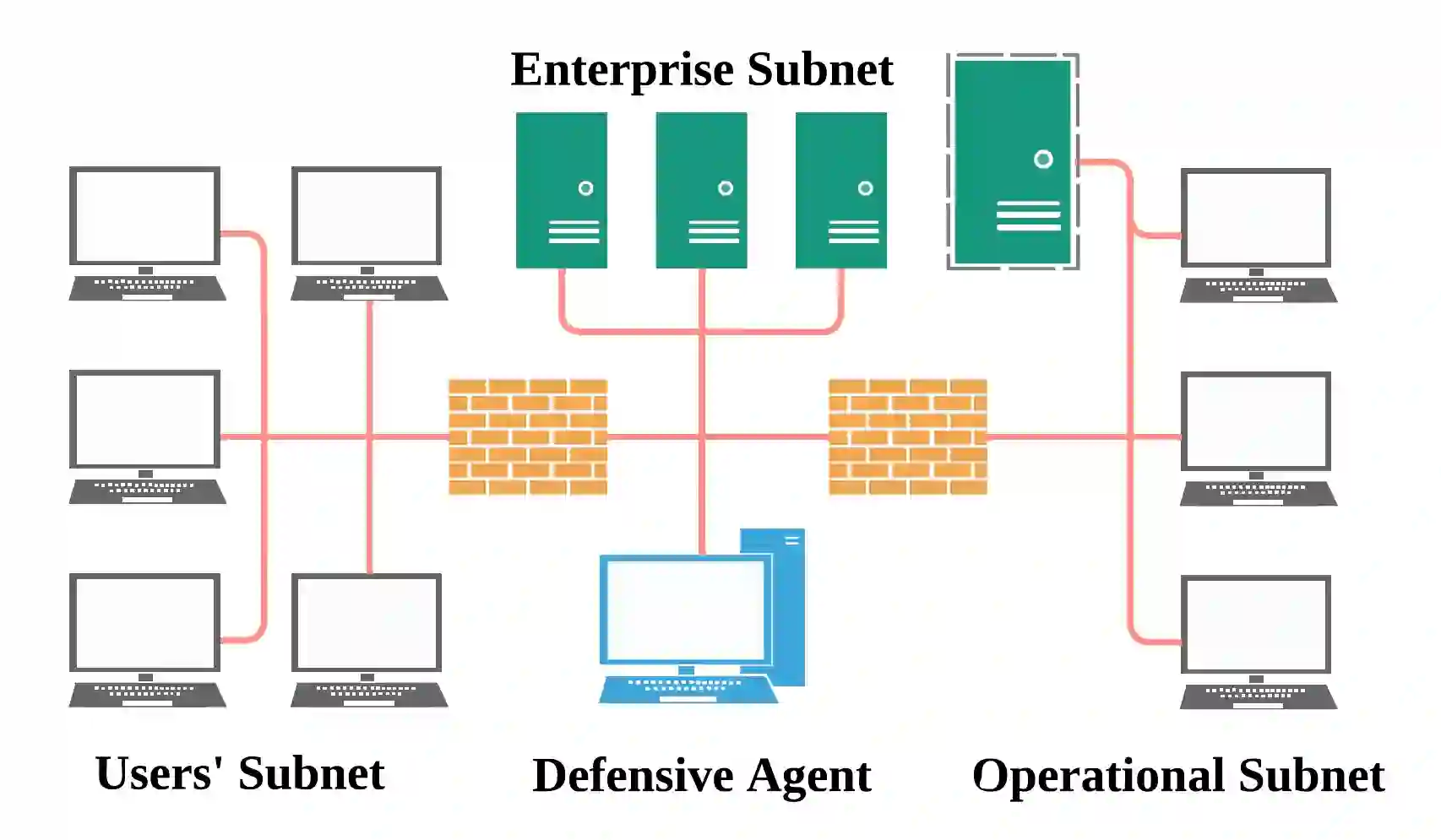
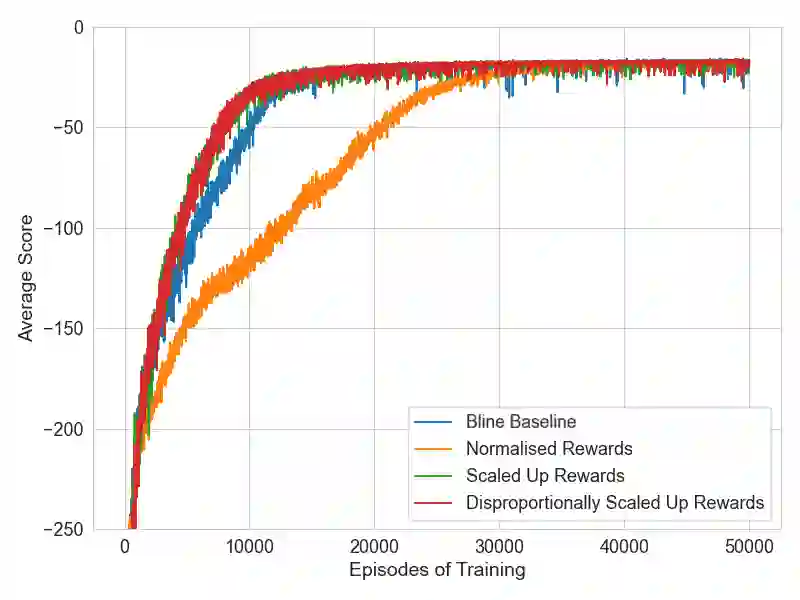
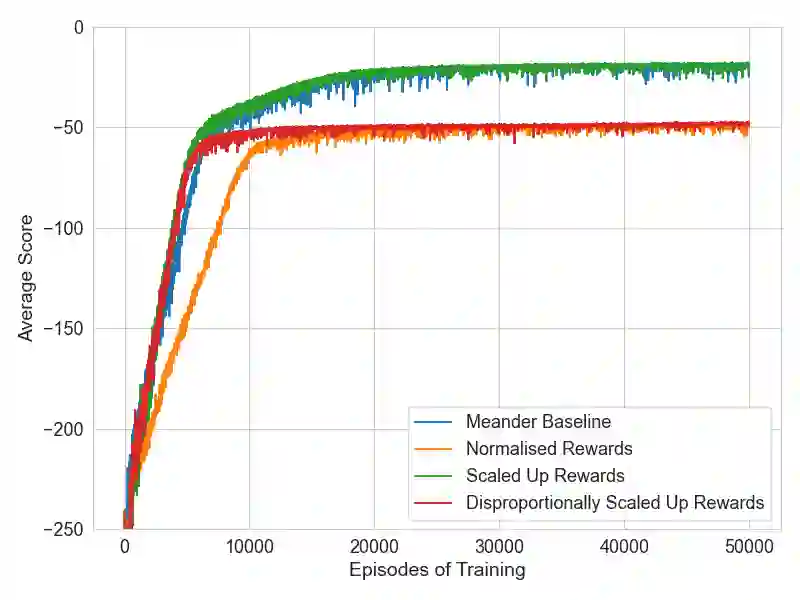
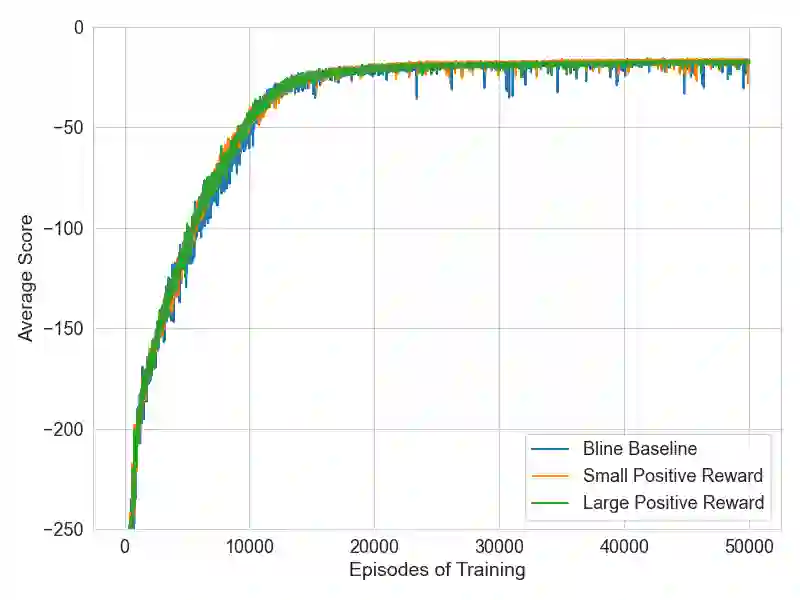
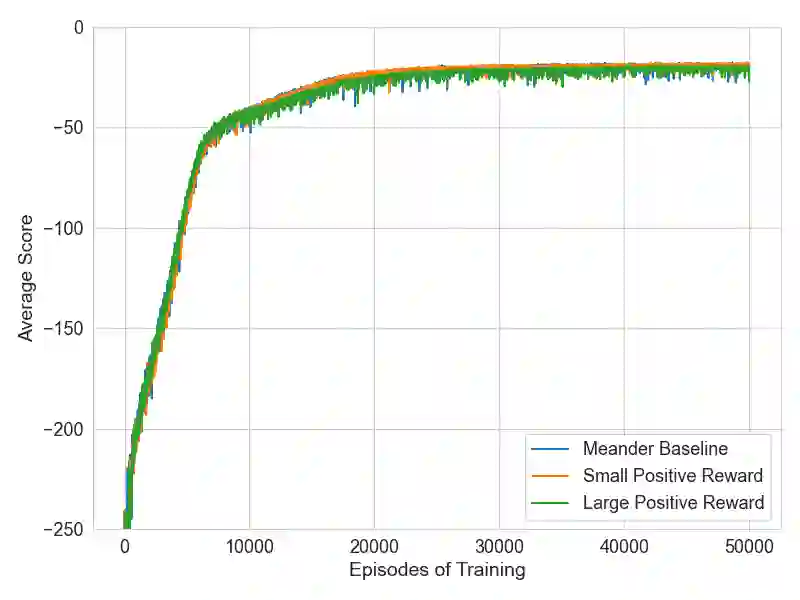
As machine learning models become more capable, they have exhibited increased potential in solving complex tasks. One of the most promising directions uses deep reinforcement learning to train autonomous agents in computer network defense tasks. This work studies the impact of the reward signal that is provided to the agents when training for this task. Due to the nature of cybersecurity tasks, the reward signal is typically 1) in the form of penalties (e.g., when a compromise occurs), and 2) distributed sparsely across each defense episode. Such reward characteristics are atypical of classic reinforcement learning tasks where the agent is regularly rewarded for progress (cf. to getting occasionally penalized for failures). We investigate reward shaping techniques that could bridge this gap so as to enable agents to train more sample-efficiently and potentially converge to a better performance. We first show that deep reinforcement learning algorithms are sensitive to the magnitude of the penalties and their relative size. Then, we combine penalties with positive external rewards and study their effect compared to penalty-only training. Finally, we evaluate intrinsic curiosity as an internal positive reward mechanism and discuss why it might not be as advantageous for high-level network monitoring tasks.
翻译:暂无翻译