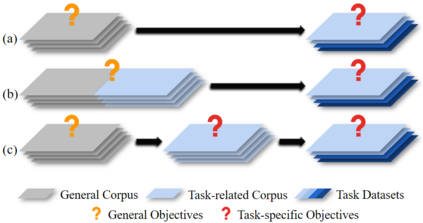
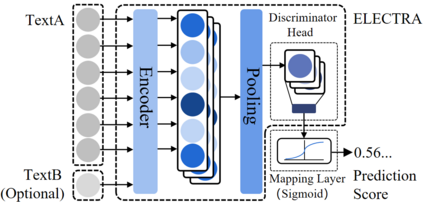
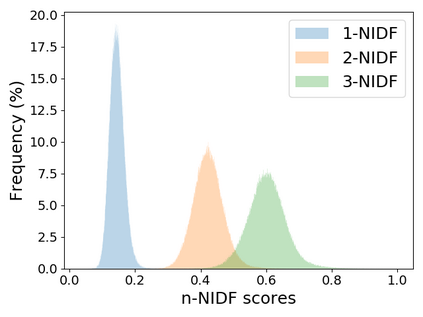
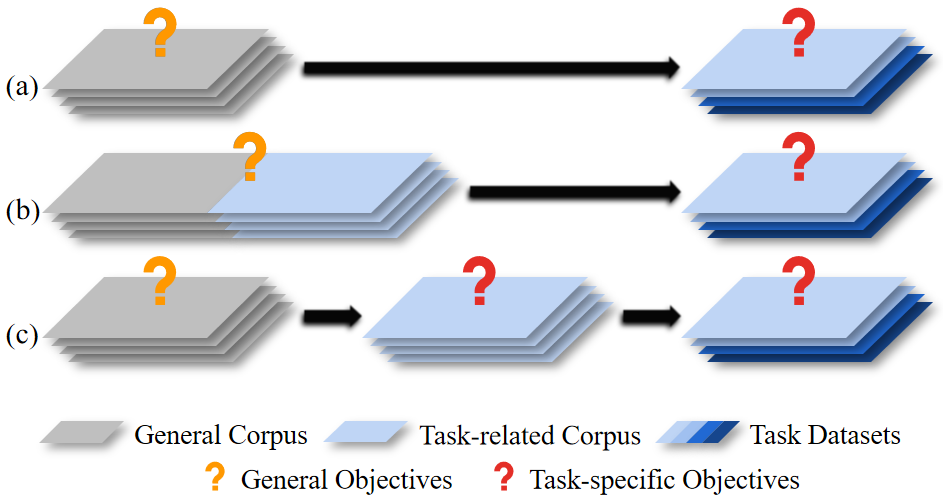
Pre-trained Language Models (PrLMs) have been widely used as backbones in lots of Natural Language Processing (NLP) tasks. The common process of utilizing PrLMs is first pre-training on large-scale general corpora with task-independent LM training objectives, then fine-tuning on task datasets with task-specific training objectives. Pre-training in a task-independent way enables the models to learn language representations, which is universal to some extent, but fails to capture crucial task-specific features in the meantime. This will lead to an incompatibility between pre-training and fine-tuning. To address this issue, we introduce task-specific pre-training on in-domain task-related corpora with task-specific objectives. This procedure is placed between the original two stages to enhance the model understanding capacity of specific tasks. In this work, we focus on Dialogue-related Natural Language Processing (DrNLP) tasks and design a Dialogue-Adaptive Pre-training Objective (DAPO) based on some important qualities for assessing dialogues which are usually ignored by general LM pre-training objectives. PrLMs with DAPO on a large in-domain dialogue corpus are then fine-tuned for downstream DrNLP tasks. Experimental results show that models with DAPO surpass those with general LM pre-training objectives and other strong baselines on downstream DrNLP tasks.
翻译:培训前语言模型(PrLMS)已被广泛用作许多自然语言处理任务(NLP)的骨干; 使用PrLMS的共同过程是,首先对大型一般公司进行关于任务独立的LM培训目标的预先培训,然后对任务数据集进行微调,确定任务特定的培训目标; 以任务独立的方式进行预先培训,使这些模式能够学习语言代表,这在一定程度上是普遍性的,但未能在同时捕捉关键的任务特点; 这将导致培训前和微调之间的不兼容性。为解决这一问题,我们开始就任务特定目标的与任务相关的内部任务相关公司进行具体任务前培训。这一程序位于最初的两个阶段,以提高具体任务的模式理解能力。在这项工作中,我们侧重于与对话相关的自然语言处理任务,并根据一些评估对话的重要质量设计了培训前先导目标(DAPPO),通常被总体培训前目标所忽视。