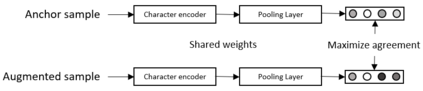
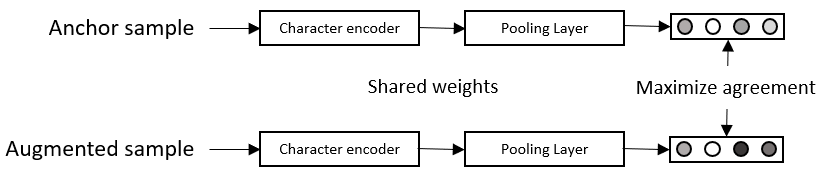
String representation Learning (SRL) is an important task in the field of Natural Language Processing, but it remains under-explored. The goal of SRL is to learn dense and low-dimensional vectors (or embeddings) for encoding character sequences. The learned representation from this task can be used in many downstream application tasks such as string similarity matching or lexical normalization. In this paper, we propose a new method for to train a SRL model by only using synthetic data. Our approach makes use of Contrastive Learning in order to maximize similarity between related strings while minimizing it for unrelated strings. We demonstrate the effectiveness of our approach by evaluating the learned representation on the task of string similarity matching. Codes, data and pretrained models will be made publicly available.
翻译:字符串代表学习(SRL)是自然语言处理领域的一项重要任务,但仍未得到充分探讨。SRL的目标是学习密集和低维矢量(或嵌入)的编码字符序列。从这一任务中学到的表述方法可用于许多下游应用任务,如字符串相似匹配或法例正常化。在本文中,我们提出了仅使用合成数据来培训SRL模式的新方法。我们的方法是利用差异学习来尽量扩大相关字符串之间的相似性,同时将相关字符串的相似性减至最小。我们通过评估在字符串相似匹配任务上学到的表述方法,展示了我们的方法的有效性。代码、数据和预先培训的模式将公布于众。