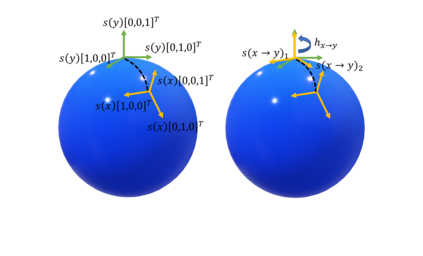
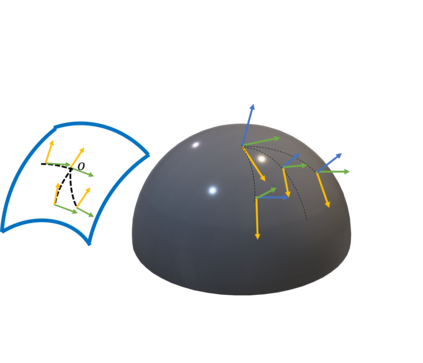
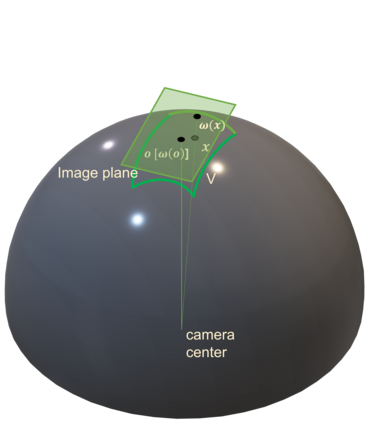
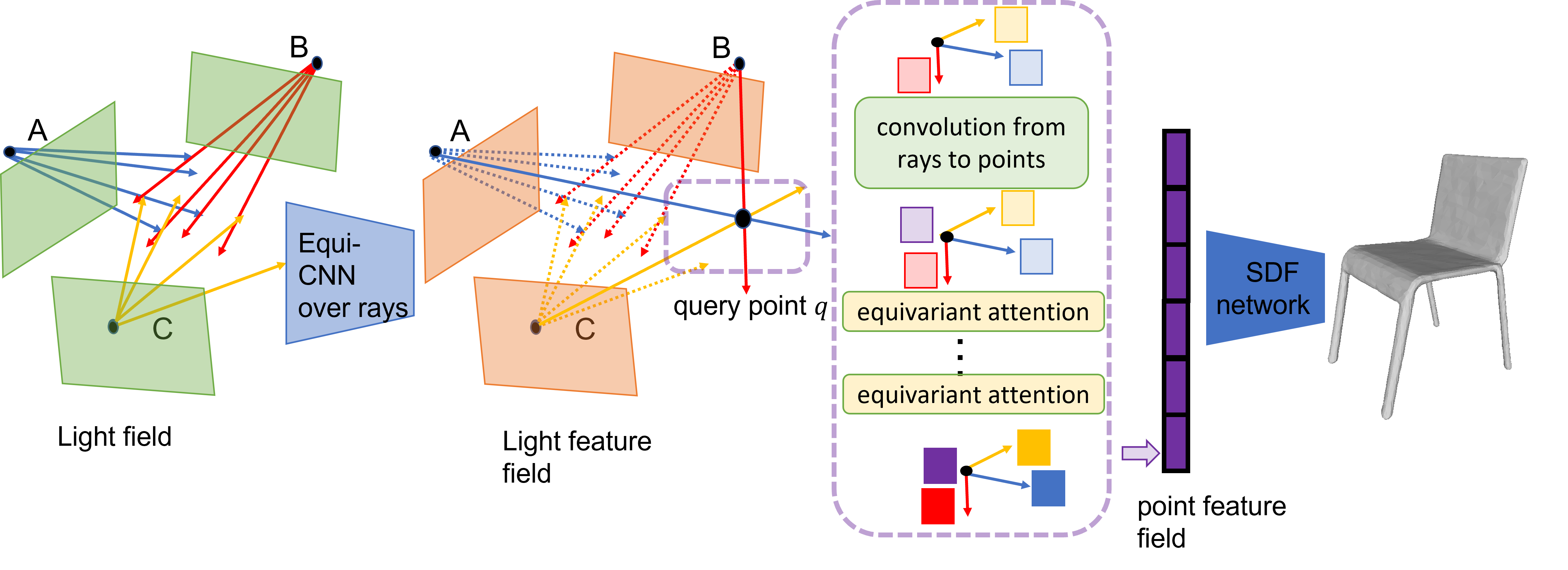
Recent progress in geometric computer vision has shown significant advances in reconstruction and novel view rendering from multiple views by capturing the scene as a neural radiance field. Such approaches have changed the paradigm of reconstruction but need a plethora of views and do not make use of object shape priors. On the other hand, deep learning has shown how to use priors in order to infer shape from single images. Such approaches, though, require that the object is reconstructed in a canonical pose or assume that object pose is known during training. In this paper, we address the problem of how to compute equivariant priors for reconstruction from a few images, given the relative poses of the cameras. Our proposed reconstruction is $SE(3)$-gauge equivariant, meaning that it is equivariant to the choice of world frame. To achieve this, we make two novel contributions to light field processing: we define light field convolution and we show how it can be approximated by intra-view $SE(2)$ convolutions because the original light field convolution is computationally and memory-wise intractable; we design a map from the light field to $\mathbb{R}^3$ that is equivariant to the transformation of the world frame and to the rotation of the views. We demonstrate equivariance by obtaining robust results in roto-translated datasets without performing transformation augmentation.
翻译:最近几何计算机愿景的进展表明,在重建方面取得了重大进步,并且从多种观点中出现了新的观点,通过将场景作为神经光亮场来捕捉,这些方法改变了重建的范式,但需要大量的观点,并且不使用对象形状的前缀。另一方面,深层次的学习表明,如何使用前缀从单一图像中推断形状。不过,这些方法要求该对象以一个罐头的形式进行重建,或假设该对象的形状在培训期间为人所知。在本文中,我们处理如何从几幅图像中计算等同的重建前缀的问题,考虑到相机的相对面貌。我们提议的重建是需要大量的观点,但需要大量的观点,而不是使用对象形状形状的形状。为了做到这一点,我们为光场处理作出了两项新的贡献:我们定义了光场演进,我们展示了它如何被内观所认识的方位值所近似,即$SE(2)美元,因为原始的光场变变和记忆可调;我们从一个光场设计了一个地图,从一个小场面到一个正值的正值变到一个正值的正值,我们通过正变的正变到正值世界的数据框架,以显示稳定的变。