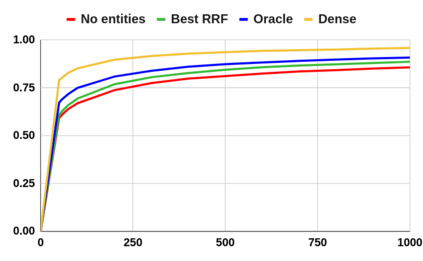
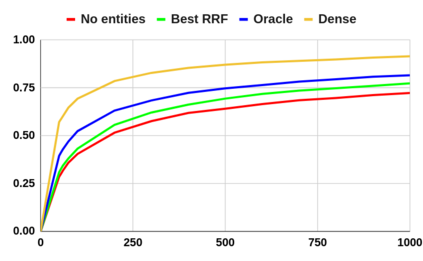
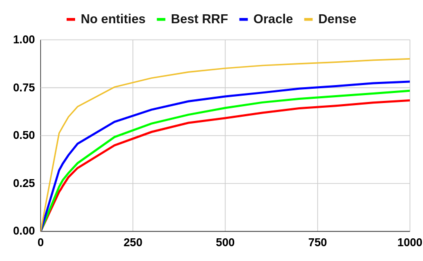
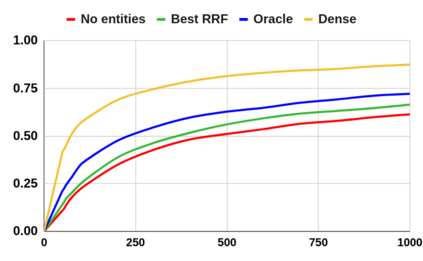
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, we propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. We employ a zero-shot end-to-end dense entity linking system for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, we believe that the effectiveness gap between sparse and dense retrievers can be narrowed. We conduct our experiments on the MS MARCO passage dataset. Since we are concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, we evaluate our results using recall@1000. Our approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work. We further demonstrate that the non-expanded and the expanded runs with both explicit and hashed entities retrieve complementary results. Consequently, we adopt a run fusion approach to maximize the benefits of entity linking.
翻译:尽管其低资源设置的优点,传统稀少的检索器尽管有其低资源设置的优点,但传统稀少的检索器取决于高维字袋(BoW)对查询和收藏的表达方式之间的精确匹配方法。因此,检索性能受到语义差异和词汇差距的限制。另一方面,基于变压器的密集检索器通过利用低维背景化的体格来大大改进信息检索任务。虽然以其相对有效性而著称,但与分散的检索器相比,它们的效率较低,缺乏概括性的问题。对于轻量的检索任务,高计算资源和时间消耗是鼓励放弃密集模型的主要障碍,尽管可能有所收获。在这项工作中,我们提议通过扩大查询和与实体关联实体的两种格式:(1) 明确和(2) 已经出现。我们使用零点对端对端对端的密集实体连接系统,以确认和模糊性的方法来增加数据。我们利用先进的连接方法,我们认为,分散和密集的检索机精度之间的效率差距是鼓励放弃大量检索结果。我们开始大规模检索系统的实验,因为我们的升级系统已经采用了。