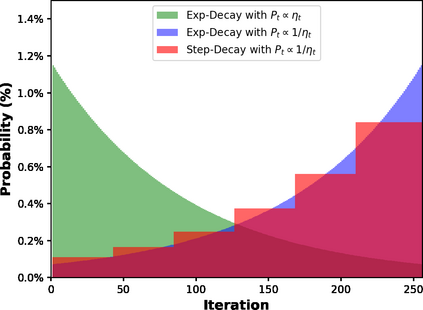
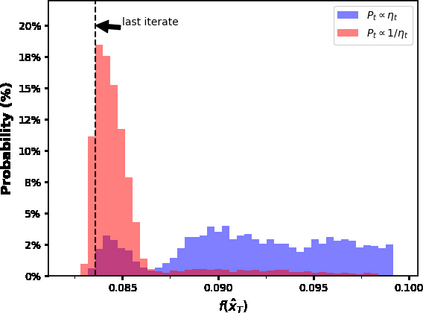
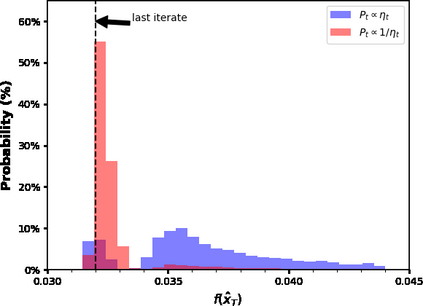
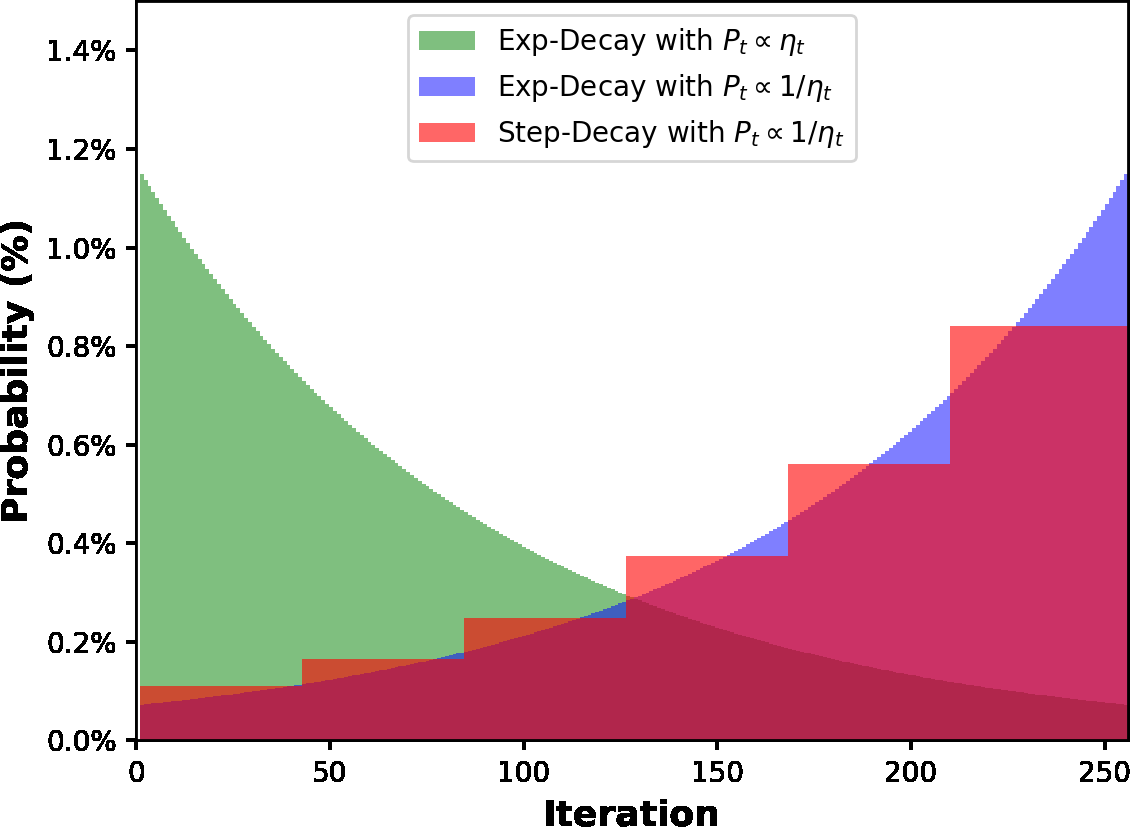
The convergence of stochastic gradient descent is highly dependent on the step-size, especially on non-convex problems such as neural network training. Step decay step-size schedules (constant and then cut) are widely used in practice because of their excellent convergence and generalization qualities, but their theoretical properties are not yet well understood. We provide the convergence results for step decay in the non-convex regime, ensuring that the gradient norm vanishes at an $\mathcal{O}(\ln T/\sqrt{T})$ rate. We also provide the convergence guarantees for general (possibly non-smooth) convex problems, ensuring an $\mathcal{O}(\ln T/\sqrt{T})$ convergence rate. Finally, in the strongly convex case, we establish an $\mathcal{O}(\ln T/T)$ rate for smooth problems, which we also prove to be tight, and an $\mathcal{O}(\ln^2 T /T)$ rate without the smoothness assumption. We illustrate the practical efficiency of the step decay step-size in several large scale deep neural network training tasks.
翻译:脉冲梯度下降的趋同高度取决于步骤大小, 特别是神经网络培训等非凝固问题。 步步衰变步级表( 固定, 然后切换) 由于其极佳的趋同性和概括性, 在实践中被广泛使用, 但是它们的理论特性还不能很好地理解 。 我们为非convex 制度中的步骤衰化提供了趋同结果, 确保梯度标准以美元/ mathcal{O} (n) T/ sqrt{T} 的速率消失。 我们还为一般( 可能非悬浮) 凝固问题提供趋同保证, 确保 $\ mathcal{O} (\ ln T/ sqrt{T} ) 的趋同率 。 最后, 在强烈的 convex 情况下, 我们为平滑问题设定了 $\ mathcal{O} (n T/ T/ T) 速率, 也证明我们很紧, 和 $\ mathcal{O} (\\ lex) rovelage- restial lavel lade rodestration rodustration laft ladestruclegle laft laft laft laft laft le laft laft compeal.