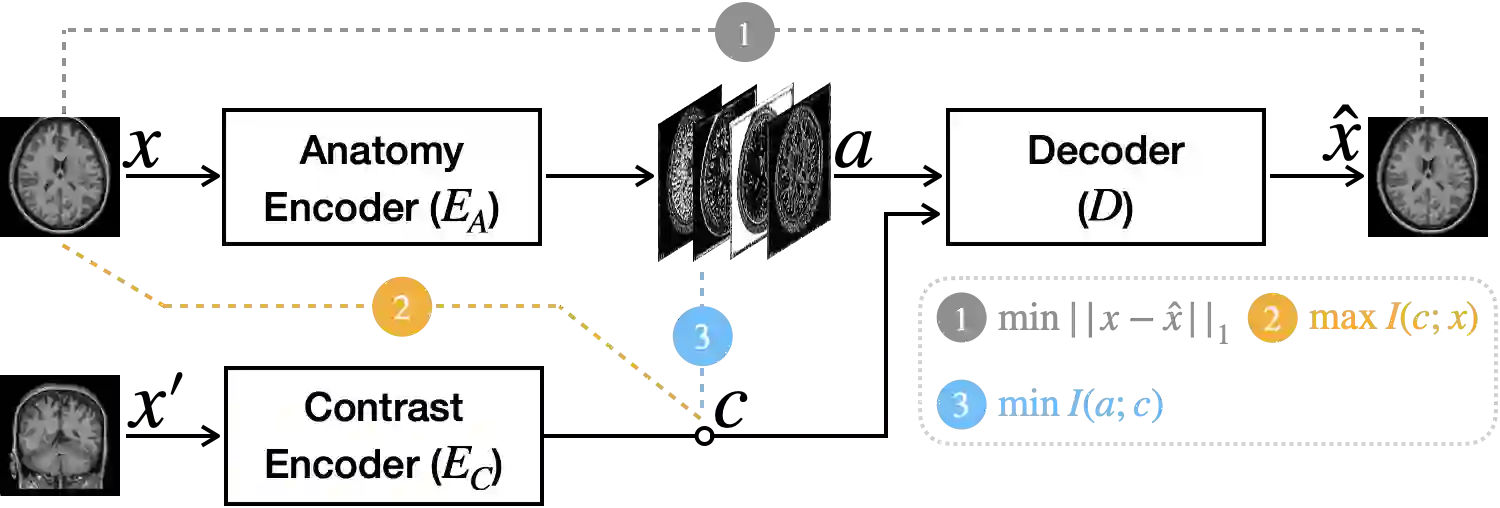
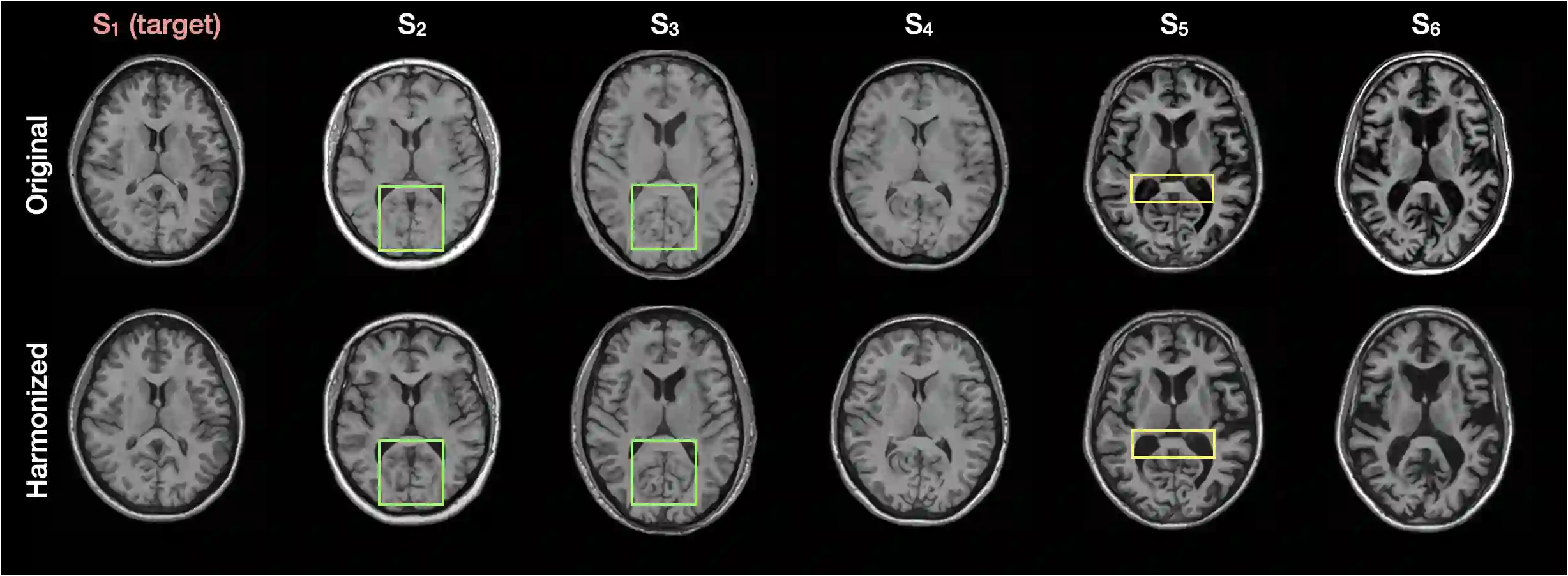
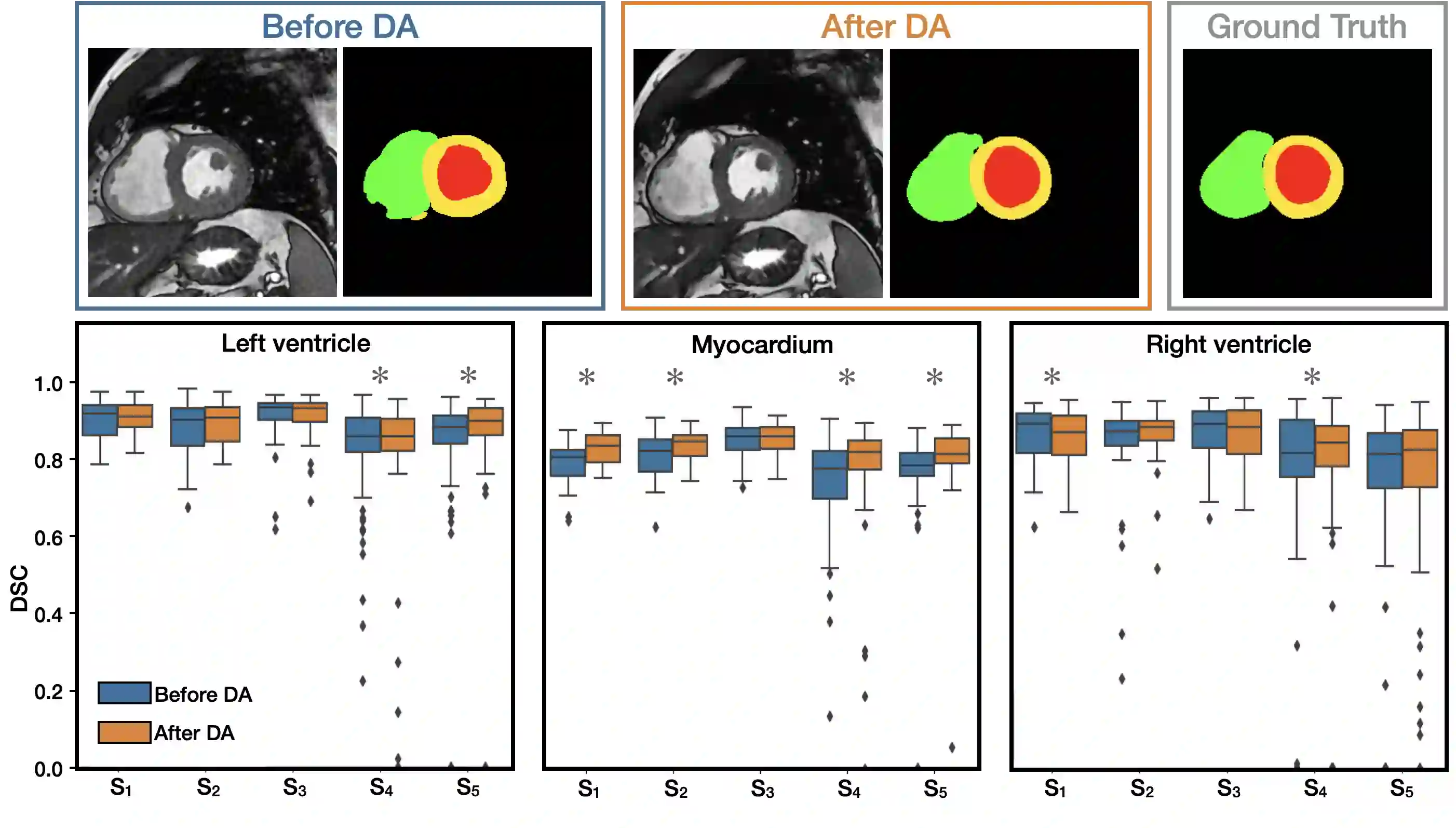
Disentangling anatomical and contrast information from medical images has gained attention recently, demonstrating benefits for various image analysis tasks. Current methods learn disentangled representations using either paired multi-modal images with the same underlying anatomy or auxiliary labels (e.g., manual delineations) to provide inductive bias for disentanglement. However, these requirements could significantly increase the time and cost in data collection and limit the applicability of these methods when such data are not available. Moreover, these methods generally do not guarantee disentanglement. In this paper, we present a novel framework that learns theoretically and practically superior disentanglement from single modality magnetic resonance images. Moreover, we propose a new information-based metric to quantitatively evaluate disentanglement. Comparisons over existing disentangling methods demonstrate that the proposed method achieves superior performance in both disentanglement and cross-domain image-to-image translation tasks.
翻译:从医学图像中分离解剖和对比信息最近引起注意,显示了各种图像分析任务的好处。目前的方法通过对齐多式图像与相同的解剖或辅助标签(例如人工划界)来提供解剖的感应偏差(不过,这些要求可以大大增加数据收集的时间和成本,并在没有这类数据时限制这些方法的适用性。此外,这些方法一般不能保证解剖。在本文件中,我们提出了一个新颖的框架,从理论上和实际上学习与单一模式磁共振图像分离的优越性。此外,我们提出了一个新的基于信息的计量标准,以定量评估解析。与现有脱钩方法的比较表明,拟议方法在解剖和交叉图像到映射翻译任务方面都取得了优异性。