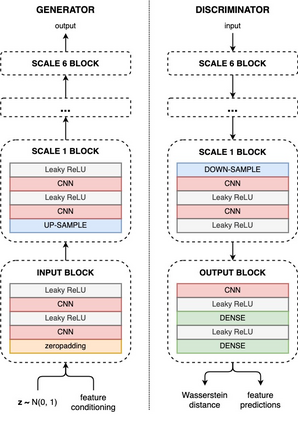
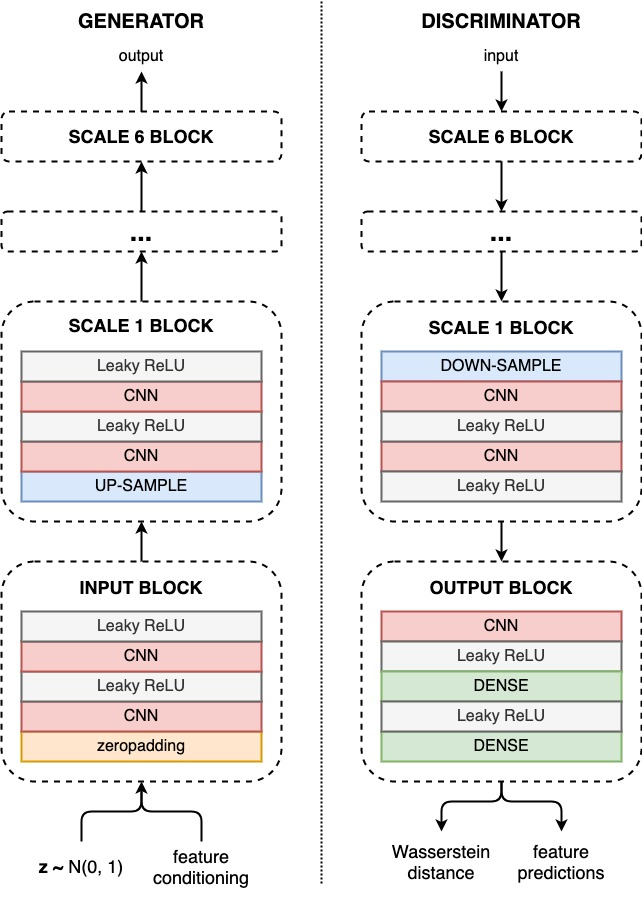
Synthetic creation of drum sounds (e.g., in drum machines) is commonly performed using analog or digital synthesis, allowing a musician to sculpt the desired timbre modifying various parameters. Typically, such parameters control low-level features of the sound and often have no musical meaning or perceptual correspondence. With the rise of Deep Learning, data-driven processing of audio emerges as an alternative to traditional signal processing. This new paradigm allows controlling the synthesis process through learned high-level features or by conditioning a model on musically relevant information. In this paper, we apply a Generative Adversarial Network to the task of audio synthesis of drum sounds. By conditioning the model on perceptual features computed with a publicly available feature-extractor, intuitive control is gained over the generation process. The experiments are carried out on a large collection of kick, snare, and cymbal sounds. We show that, compared to a specific prior work based on a U-Net architecture, our approach considerably improves the quality of the generated drum samples, and that the conditional input indeed shapes the perceptual characteristics of the sounds. Also, we provide audio examples and release the code used in our experiments.
翻译:合成鼓声(例如,在鼓机中)的合成创造通常使用模拟或数字合成方式进行,使音乐家能够雕塑理想的音质,修改各种参数。通常,这些参数控制声音的低水平特征,通常没有音乐意义或感知性通信。随着深层学习的兴起,以数据驱动的方式处理音响作为传统信号处理的替代物。这一新模式允许通过高层次的学习特征或通过对音乐相关信息的模型进行调节来控制合成过程。在本文中,我们运用创制反反声网络来完成鼓声合成任务。通过对以公开的地貌吸引器计算出的感知性特征模型进行调整,对生成过程进行直觉控制。实验是在大量收集踢、鼻和细胞声音的基础上进行的。我们显示,与基于U-Net结构的具体先前工作相比,我们的方法大大改进了所生成的鼓样的质量,而有条件的输入确实塑造了声音的感知性特征。此外,我们还利用了音学和细胞声音释放的代码。