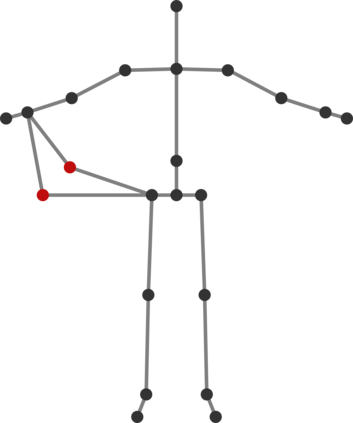
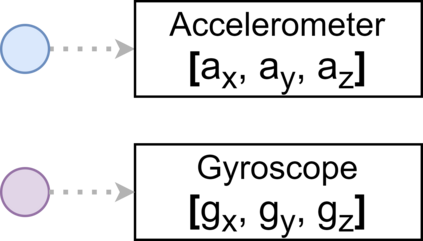
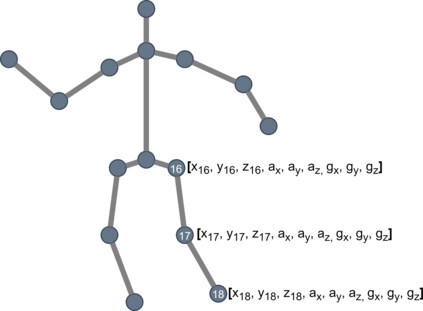
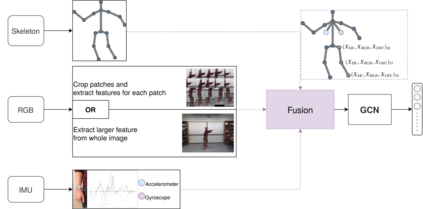
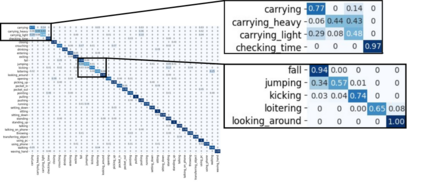
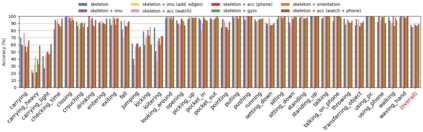
In this paper, we present Fusion-GCN, an approach for multimodal action recognition using Graph Convolutional Networks (GCNs). Action recognition methods based around GCNs recently yielded state-of-the-art performance for skeleton-based action recognition. With Fusion-GCN, we propose to integrate various sensor data modalities into a graph that is trained using a GCN model for multi-modal action recognition. Additional sensor measurements are incorporated into the graph representation, either on a channel dimension (introducing additional node attributes) or spatial dimension (introducing new nodes). Fusion-GCN was evaluated on two public available datasets, the UTD-MHAD- and MMACT datasets, and demonstrates flexible fusion of RGB sequences, inertial measurements and skeleton sequences. Our approach gets comparable results on the UTD-MHAD dataset and improves the baseline on the large-scale MMACT dataset by a significant margin of up to 12.37% (F1-Measure) with the fusion of skeleton estimates and accelerometer measurements.
翻译:在本文中,我们介绍“Fusion-GCN”,这是一种利用“图变网络”确认多式联运行动的方法;基于“GCN”的行动识别方法,最近以“GCN”为基础,产生了基于骨骼的动作识别的最先进性能;与“GCN”结合,我们提议将各种传感器数据模式纳入一个使用“GCN”多模式行动识别模型培训的图表中;在“图示”中包含更多的传感器测量,或者在“频道”层面(引入额外的节点属性),或者在“空间”层面(引入新的节点),对“Fsion-GCN”进行了评估;对两个公开数据集(UTD-MHAD-和MMACT数据集)进行了评估,并展示了RGB序列、惯性测量和骨骼序列的灵活融合;我们的方法在“UTD-MHAD”数据集上取得了可比的结果,并改进了大规模MMACT数据集的基线,其基质估计和加速度测量的幅度高达12.37%(F1-计量)。