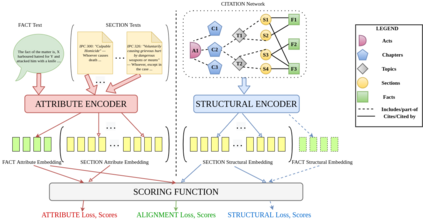
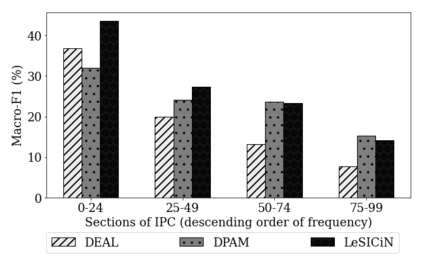
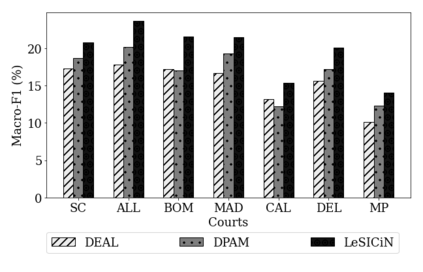
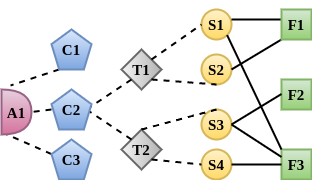
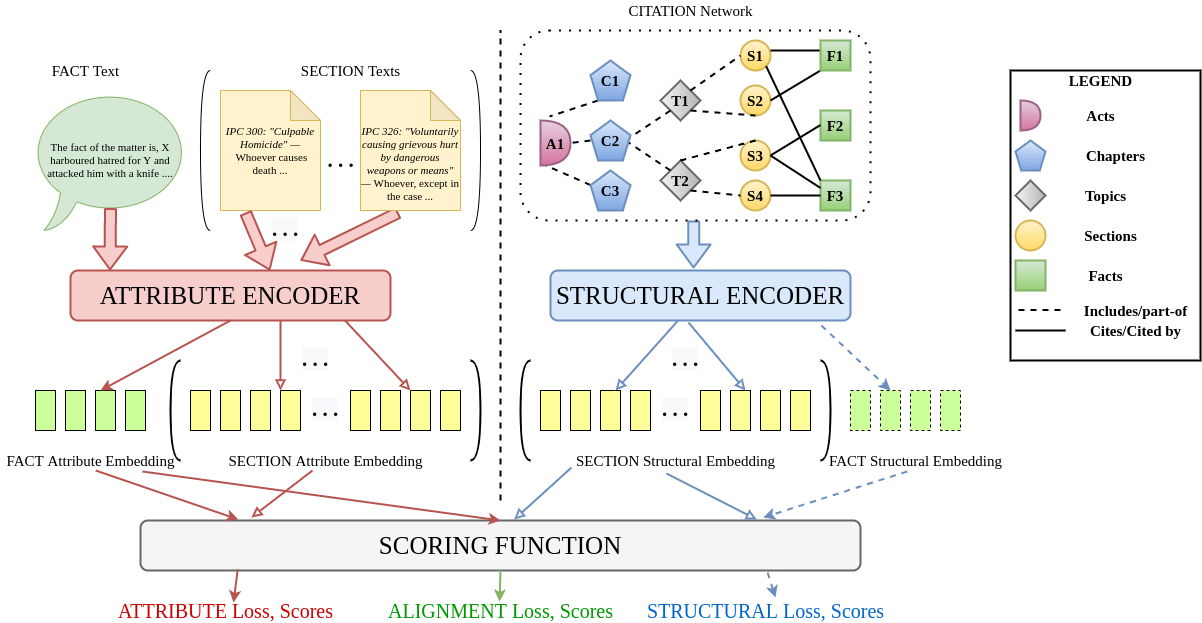
The task of Legal Statute Identification (LSI) aims to identify the legal statutes that are relevant to a given description of Facts or evidence of a legal case. Existing methods only utilize the textual content of Facts and legal articles to guide such a task. However, the citation network among case documents and legal statutes is a rich source of additional information, which is not considered by existing models. In this work, we take the first step towards utilising both the text and the legal citation network for the LSI task. We curate a large novel dataset for this task, including Facts of cases from several major Indian Courts of Law, and statutes from the Indian Penal Code (IPC). Modeling the statutes and training documents as a heterogeneous graph, our proposed model LeSICiN can learn rich textual and graphical features, and can also tune itself to correlate these features. Thereafter, the model can be used to inductively predict links between test documents (new nodes whose graphical features are not available to the model) and statutes (existing nodes). Extensive experiments on the dataset show that our model comfortably outperforms several state-of-the-art baselines, by exploiting the graphical structure along with textual features. The dataset and our codes are available at https://github.com/Law-AI/LeSICiN.
翻译:法律法规识别(LSI)的任务是确定与特定描述事实或法律案件证据有关的法规; 现有方法仅利用《事实》和法律条文的文字内容和法律条文的文字内容来指导这项任务; 然而,案例文件和法规之间的引用网络是额外信息的丰富来源,现有模式没有考虑到这一点; 在这项工作中,我们迈出第一步,利用文本和法律引用网络来完成LSI的任务; 我们为这项任务制作了一个庞大的新数据集,包括几个主要印度法院的案例和印度刑法(LOC)的法规。 将法规和培训文件建模成一个混合图,我们提议的模型LeSICiN可以学习丰富的文字和图形特征,也可以调和这些特征。 之后,该模型可以用来对测试文件(模型没有图表特征的新点)和法规(现有节点)之间的联系进行感化预测。 有关数据集的广泛实验显示,我们的模型比一些州/州/州/州/州/州/州/州标准系统数据库基准要更精确,通过利用我们的图表/州/州/州/州/州/州/州/州标准数据库基准。