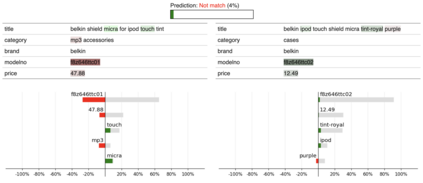
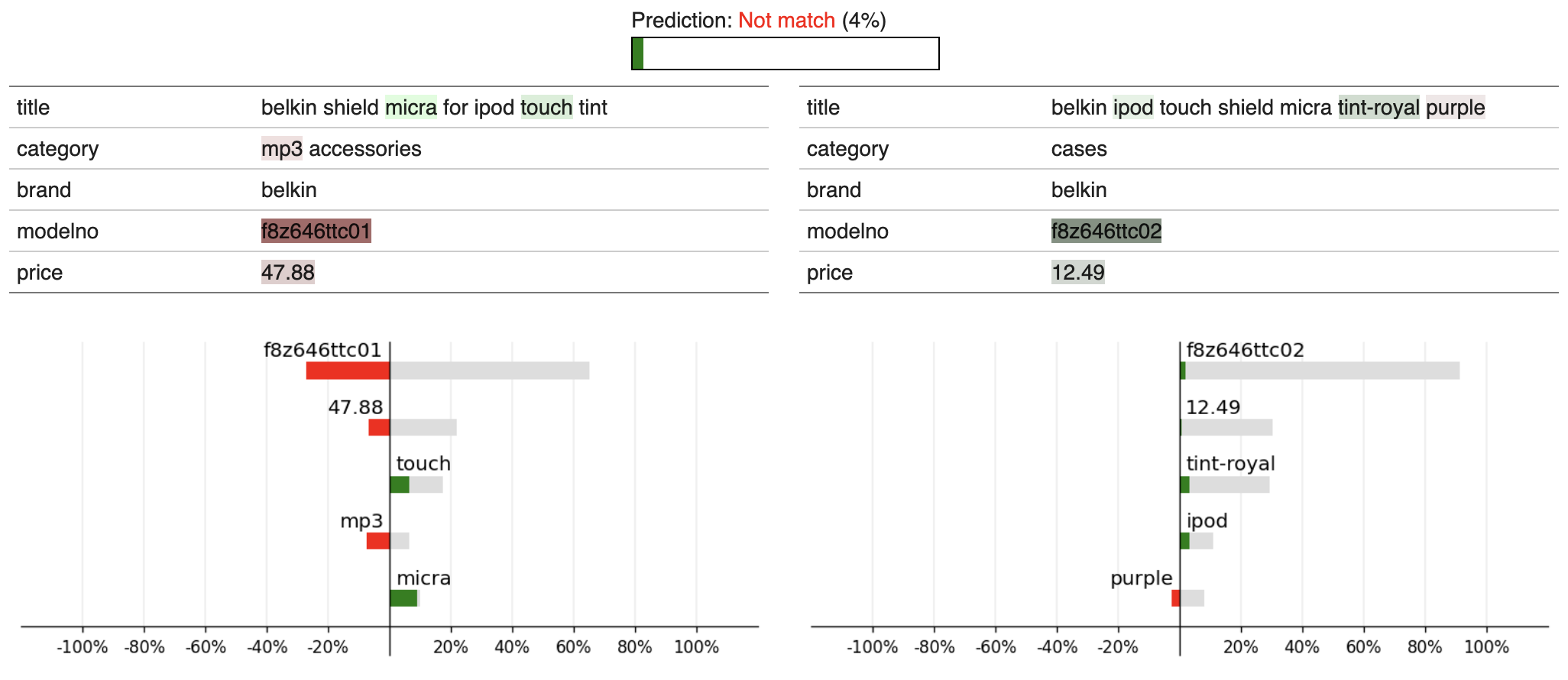
State-of-the-art entity matching (EM) methods are hard to interpret, and there is significant value in bringing explainable AI to EM. Unfortunately, most popular explainability methods do not work well out of the box for EM and need adaptation. In this paper, we identify three challenges of applying local post hoc feature attribution methods to entity matching: cross-record interaction effects, non-match explanations, and variation in sensitivity. We propose our novel model-agnostic and schema-flexible method LEMON that addresses all three challenges by (i) producing dual explanations to avoid cross-record interaction effects, (ii) introducing the novel concept of attribution potential to explain how two records could have matched, and (iii) automatically choosing explanation granularity to match the sensitivity of the matcher and record pair in question. Experiments on public datasets demonstrate that the proposed method is more faithful to the matcher and does a better job of helping users understand the decision boundary of the matcher than previous work. Furthermore, user studies show that the rate at which human subjects can construct counterfactual examples after seeing an explanation from our proposed method increases from 54% to 64% for matches and from 15% to 49% for non-matches compared to explanations from a standard adaptation of LIME.
翻译:最先进的实体匹配(EM)方法很难解释,将可解释的AI 方法引入EM。 不幸的是,大多数流行的解释方法在EM的框中效果不佳,需要调整。 在本文件中,我们确定了对实体匹配应用本地特定特性归属方法的三个挑战:交叉记录互动效应、非匹配解释和敏感度的变异。我们建议了我们的新颖的模型-不可知性和形式灵活方法LEMON,该方法通过(一) 产生双重解释,以避免交叉记录互动效应,(二) 引入新的归属潜力概念,以解释两种记录如何匹配,(三) 自动选择解释颗粒性,以匹配匹配匹配对象的敏感度和相关记录配对。对公共数据集的实验表明,拟议方法更忠实于匹配者,并且比以往工作更有助于用户理解匹配者的决定界限。此外,用户研究表明,在看到从我们拟议的方法解释从54%到15 %的标准调整率之后,人类主体能够构建反事实例子的速度,从我们拟议方法从54%到15 %的对比比标准调整率。