论文浅尝 | Hike: A Hybrid Human-Machine Method for Entity Alignment

Zhuang Y,Li G, Zhong Z, et al. Hike: A Hybrid Human-Machine Method for Entity Alignmentin Large-Scale Knowledge Bases[C]// ACM, 2017:1917-1926. ( CIKM 2017 )
论文链接:http://dbgroup.cs.tsinghua.edu.cn/ligl/crowdalign.pdf
Motivation
随着语义网络的迅速发展,越来越多的大规模知识图谱公开发布,为了综合使用多个来源的知识图谱,首要步骤就是进行实体对齐(Entity Alignment)。近年来,许多研究者提出了自动化的实体对齐方法,但是,由于知识图谱数据的不均衡性,导致此类方法对齐质量较低,特别是召回率(Recall)。因此,可考虑借助于众包平台提升对齐效果,文章提出了一个人机协作的方法,对大规模知识图谱进行实体对齐。
Framework
方法主要流程如图所示:
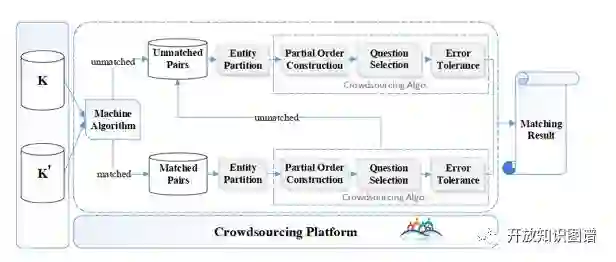
首先,通过机器学习方法对知识库进行粗略的实体对齐,然后分别将以对齐实体对(MatchedPairs)和未对齐实体对(UnmatchedPairs)放入众包平台,让人进行判断。两条流水线的步骤类似,主要包括四个部分:实体集划分(EntityPartition)、建立偏序(PartialOrder Construction)、问题选择(QuestionSelection)、容错处理(ErrorTolerance)。
实体集划分的目的是将同类的实体聚类到一个集合,实体对齐只在集合内部进行,集合之间不进行对齐操作。实体集划分的依据是属性,通常同一类实体的属性是相似的。
偏序定义如下:
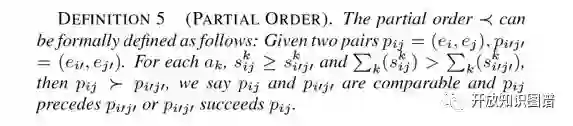
建立偏序的目的在于找出最具有推理期望(InferenceExpectation)的实体对,偏序集实例如下
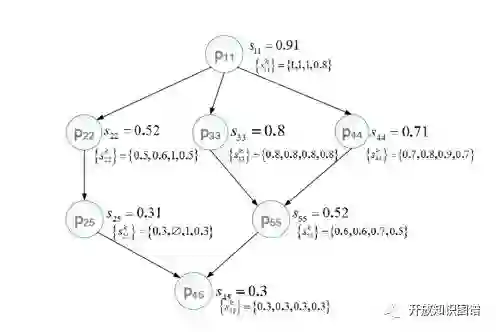
其中,如果P11被判断为Unmatch,则所有偏序小于P11的节点都可以推断为unmatch。反之,如果P45被推断为Match,则所有偏序大于P45的节点都可以推断为Match。
推理期望公式如下:
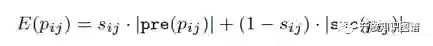
其中,pre和suc分别表示前驱和后继节点。
对于问题选择,文章提出了两个贪心算法,分别为一次选一个节点以及一次选多个节点。算法如下:


Experiment
数据集:Yago 、 DBPedia
对比方法:PARIS、PBA
众包平台:ChinaCrowds
评估问题选择方法:
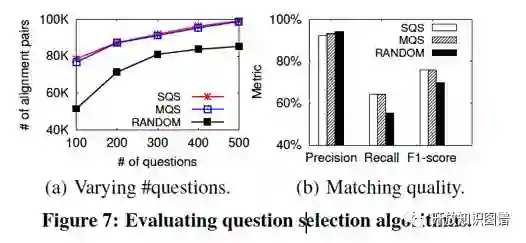
可以看到,两个贪心算法差别不大,但是比随机选择性能好。
评估问题集大小:
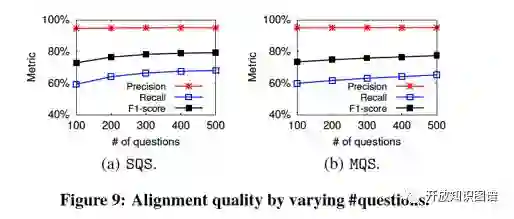
随着问题集合的增加,精确率、召回率、F值均有提升。
评估实体对齐结果:
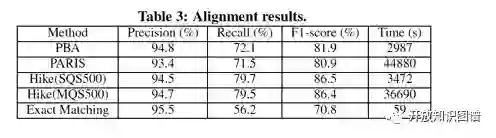
实验表明,各项评估指标具有提升,证实了人机协作的有效性,但是MQS算法复杂度太高,导致运行时间过长。
本文作者:罗丹,浙江大学硕士,研究方向:机器学习,知识图谱。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


