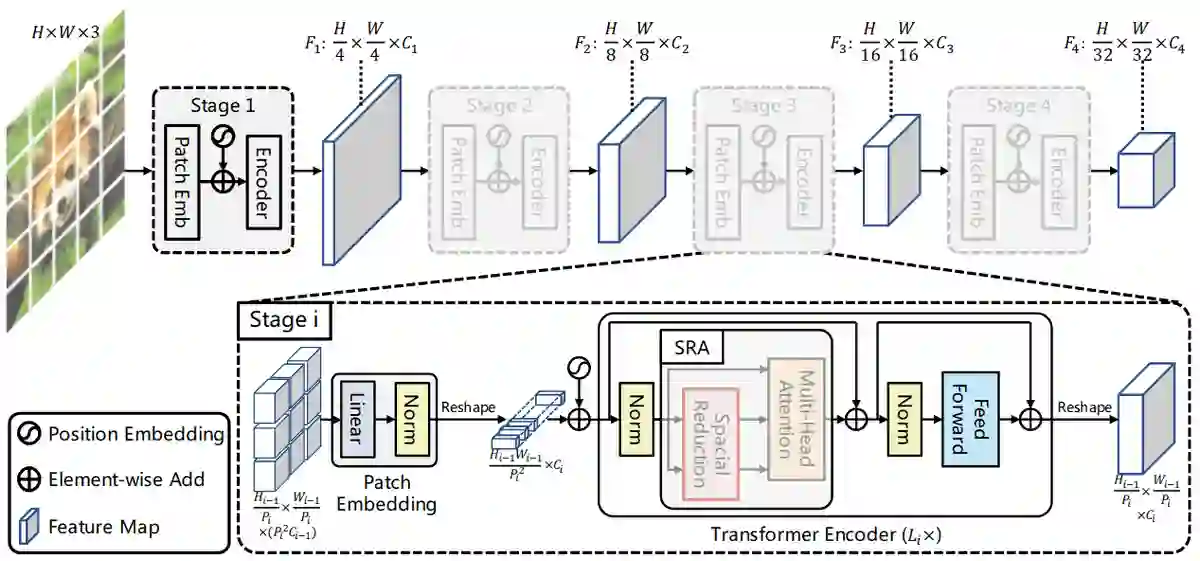
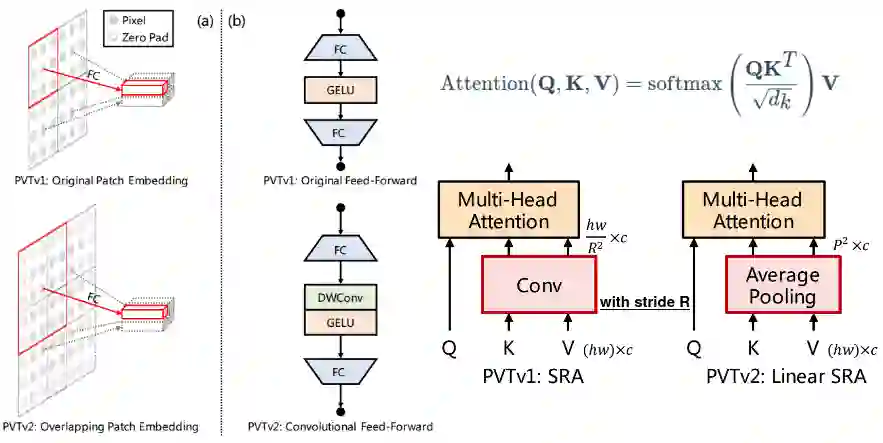
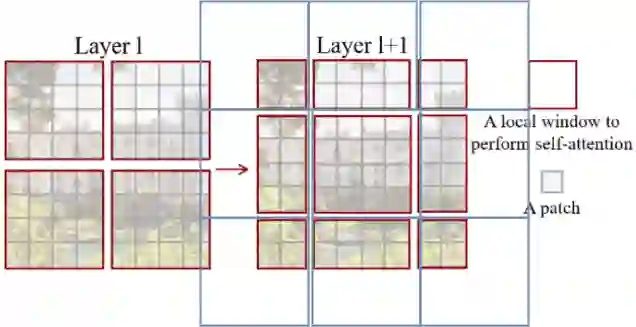
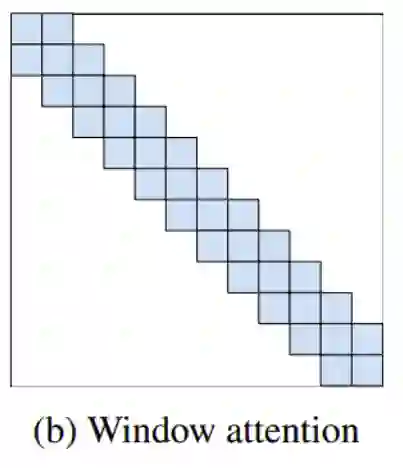
Transformer, an attention-based encoder-decoder architecture, has not only revolutionized the field of natural language processing (NLP), but has also done some pioneering work in the field of computer vision (CV). Compared to convolutional neural networks (CNNs), the Vision Transformer (ViT) relies on excellent modeling capabilities to achieve very good performance on several benchmarks such as ImageNet, COCO, and ADE20k. ViT is inspired by the self-attention mechanism in natural language processing, where word embeddings are replaced with patch embeddings. This paper reviews the derivatives of ViT and the cross-applications of ViT with other fields.
翻译:变异器是一个关注的编码器解码器结构,它不仅使自然语言处理领域发生了革命性的变化,而且还在计算机视觉领域做了一些开拓性的工作。 与进化神经网络相比,愿景变异器依靠极好的模型能力,在图像网络、COCO和ADE20k等若干基准上取得良好的业绩。 ViT受到自然语言处理中自我注意机制的启发,在自然语言处理中,文字嵌入被补丁嵌入取代。本文回顾了ViT的衍生物以及ViT与其他领域的交叉应用。